image classification models总结
本博客旨在记录自己在了解image classification这个术语computer vision的一个子任务中常见的模型。耳熟能详的就是ResNet,VGG,Inception,MobileNet,
Efficientnet。每一个模型之间有什么区别,他们自身又有哪些变种,比如VGG,它拥有VGG16,VGG19等,ResNet又有很多,单是查看Tensorflow的官方文档就会发现在tf.keras.applications模块下,就有很多模型架构可选(也都有预训练参数)。整理这个博客的目的在于让自己对这些模型之间的差别有所了解,这样在不同的任务中才会知道使用什么样的模型架构来handle自己的数据。
在整理这篇博客的过程中,我也去搜了有没有image classification这个单任务上的review文章,文章都挺多的,筛选之后推荐这篇Review of Image
Classification Algorithms Based on Convolutional Neural
Networks.这篇文章主要是介绍基于CNN的一些模型,共有三个章节。重点是第二章节梳理了CNN-based的一些模型,包括本文想要cover的VGG,inception,resnet,mobilenet。重点关注图像分类算法的小伙伴可以通读一下这篇文章。

VGG
首次提出在2014年的paper
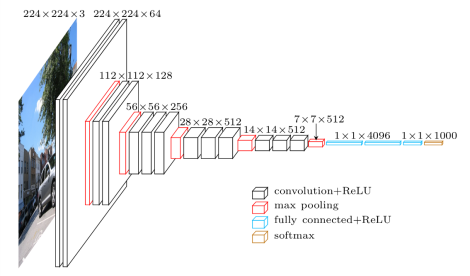
上图中包含13个卷积层和3个全连接层,是VGG16的结构。而VGG19包含了16个卷积层和3个全连接层:
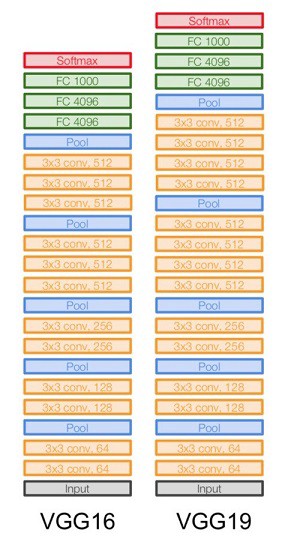
VGG系列就是VGG16和VGG19,两者的区别在于19用了更多的卷积层。Tensorflow也提供了这两个模型的黑盒子实现供大家使用。
ResNet
首次提出在2016年的paper,其中最重要的就是网络中的residual block:
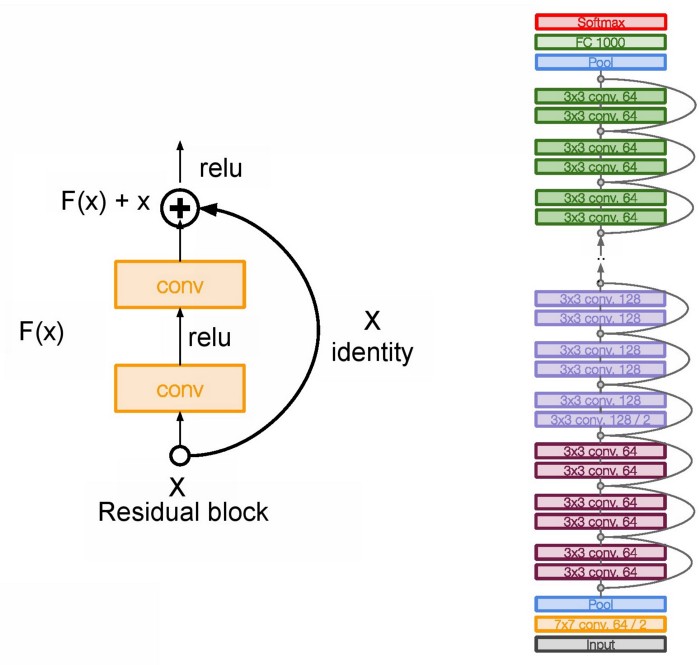
在作者的原文中我们可以发现,文章中提出的Resnet是34层,也就是ResNet34。在具体实现的时候,作者在每一个卷积操作之后(激活函数之前)加上了batch
Normalization。在Module: tf.keras.applications.resnetTensorflow
applications
resnet中现在只有ResNet101,152,50三个版本,其中ResNet50和ResNet34的区别在于:前者使用三个卷积一个block,后者是2个卷积一个block.
ResNet50表现更优异。ResNet101和ResNet152在一个block内使用了更多的卷积layer。
以上所说的都是resnet v1,后来同一个作者又发表了Identity Mappings in Deep
Residual Networks,提出了ResNet
v2。同样我们在tensorflow中也可以看到模块Module: tf.keras.applications.resnet_v2,同样的也有50,101,152三个版本的model。
v1和v2的区别在于:
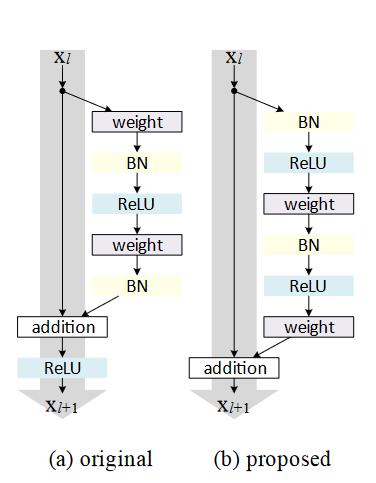
以上只是概念上的解释,看代码会更合适一点,其中Deep Residual Learning for Image Recognition文章中也给出了34,50,101,152等几个模型在实现中注意的细节:
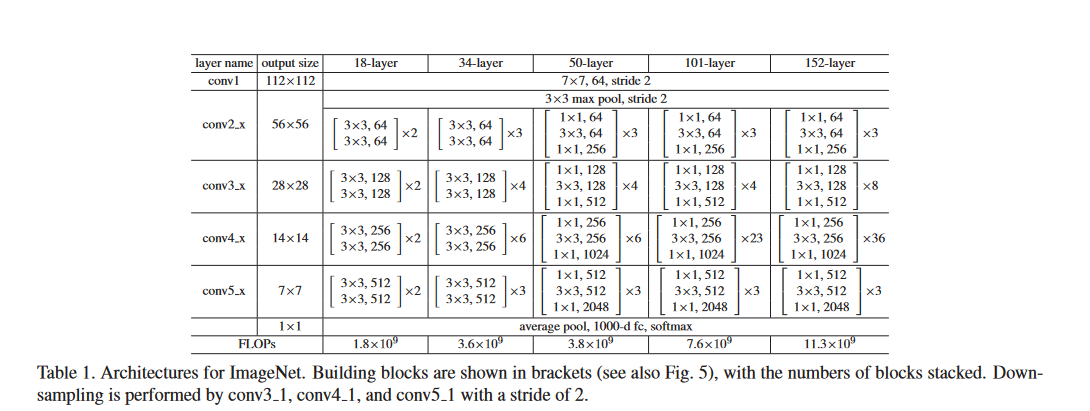
ResNet34 V1中,一个resnet block是由两个卷积layer组成的,同时它和V2的一个区别就在于X进来后就先进行卷积运算,也就是上图中的weight
1 | import tensorflow as tf |
Inception
已经有不少博客在科普Inception系列模型的区别A Simple Guide to the Versions of the Inception Network
首先提出该模型的是2014年的Going deeper with
convolutions Inception
V1(GoogleNet),然后又分别有了好几个变体:Inception V2,Inception V3,Inception V4,Inception-ResNet-v2。和ResNet一样,Inception网络中一个重要的module是Inception Module:
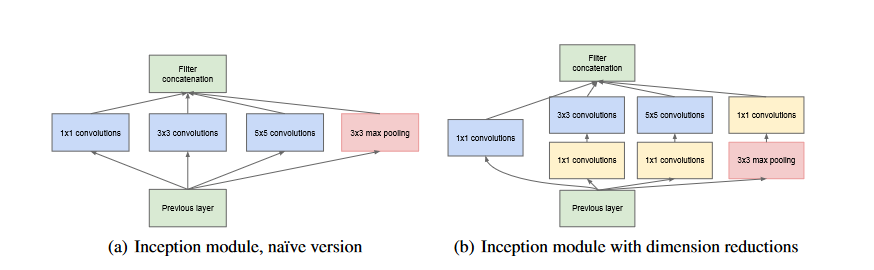
其中这些Network中被广泛使用的是Inception_v3和Inception-ResNet-v2.
MobileNet
The idea behind MobileNet is to use depthwise separable convolutions to build loghter deep neural networks. In regular convolutional layer, the convolution kernel or filter is applied to all of the channels of the input image, by doing weighted sum of the input pixels with the filter and then slides to the next input pixels across the images.MobileNet uses this regular convolution only in the first layer. The next layers are the depthwise separable convolutions which are the combination of the depthwise and pointwise convolution. The depthwise convolution does the convolution on each channel separately. If the image has three channels, therefore, the output image also has three channels. This depthwise convolution is used to filter the input channels. The next step is the pointwise convolution, which is similar to the regular convolution but with a 1x1 filter. The purpose of pointwise convolution is to merge the output channels of the depthwise convolution to create new features. By doing so, the computational work needed to be done is less than the regular convolutional networks.
MobileNet使用了两种卷积形式,depthwise和pointwise,后者就是我们常见的卷积操作,只是使用的是1✖1的卷积核,input
image有多少个channel,filter就会延展为几个channel,比如输入进来的channel数是3,那么一个3*3大小的filter就会extend成3✖3✖3的一个立方体,然后这27个数分别禹输入image对应的区域做乘积之后相加取和。但是depthwise卷积是对每一个channel分别做卷积,如果输入图片有三个channel,那么输出的也会是三个channel。如图:
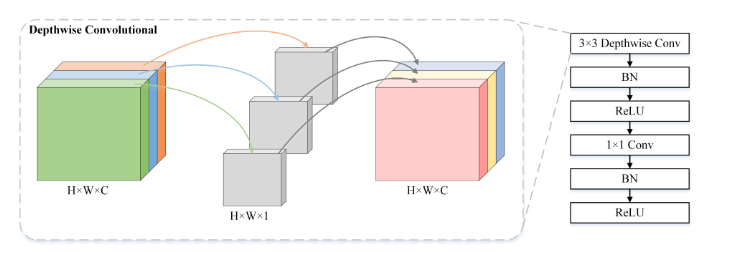
tensorflow中有DepthwiseConv2D这个layer,它对于depthwise convolution的解释是:
Depthwise convolution is a type of convolution in which each input channel is convolved with a different kernel (called a depthwise kernel). You can understand depthwise convolution as the first step in a depthwise separable convolution.
MobileNetV2主要引进了Inverted residuals和linear bottlenecks去解决在depthwise卷积操作中卷积核的参数往往是0的问题
other topics
在阅读Review of Image Classification Algorithms Based on Convolutional Neural Networks的最后一章节时,作者不仅介绍了现在research和industry领域用的比较多的image classification的模型,也给出了各个模型在image-net数据集上的accuracy。在总结章,作者还提出了一些结论性的发现,我觉得蛮收益的,将文章的观点整理在这里。
- 2012年到2017年主要提供了日后用于分类的basic CNN模型架构,这期间的模型架构有2012的alexnet,2014年的vgg,2014年的inception,2015年的resnet,2017年提出了attention加cnn的架构
- attention加入到cnn之后形成了新的模型,也因此提高了模型的performance。现在很多模型会将SE block嵌入到模型架构中去,我查了下这个SE block是SEnet中的一个block,squeeze and excitation block。SEnet是在2017年提出的,这个知识点待补充
- 超参数的选择对于CNN网络的performance影响很大,很多的工作在着力于减少超参数的个数以及replace them with other composite coefficients。
- 手动设计一个performance很好的网络往往需要很多effort,NAS search (neural architecture search)可以让这个过程变得更简单
- 想要提升模型的performance,不仅仅需要将关注力放在模型架构的设计上,data augmentation,transfer learning,training strategies也可以帮助我们提高模型的准确度。在transfer learning上,paper: Large Scale Learning of General Visual Representations for Transfer 总结了一些在不同的task上如何利用transfer learning取得很好的performance的办法。
CNN model 还面临的挑战:
- lightweight models比如mobileNet系列的轻量级模型往往需要牺牲accuracy来提高efficiency。未来在embedded系统上,CNN的运行效率值得去explore
- cnn模型在semi-supervised和unsupervised上的发挥不如NLP领域。
future directions:
- 重视vision transformer. 如何将卷积和transformer有效结合起来是当前的一个热点。目前的SOTA network是 CoAtNet,在image net数据集上的accuracy是90.88,确实是目前在image net数据集上performance最高的模型架构。值得读一下,mark!
- 有一些关于CNN的传统技术可能会成为阻碍CNN发展的重要因素,诸如:activation function的选择,dropout,batch normalization。
SENet 2017
原文 SEnet,是由自动驾驶公司Momenta在2017年公布的一种全新的图像识别结构,它通过对特征通道间的相关性进行建模,把重要的特征进行强化来提升准确率。这个结构是2017 ILSVR竞赛的冠军,top5的错误率达到了2.251%,比2016年的第一名还要低25%,可谓提升巨大。