instruction-following language models
nlp领域很多新出现的名词或者火热的研究方向,没有一个统一的标准。我在接触这些新的概念的时候往往会很糊涂,需要找大量的文献来看,然后捋清楚模型或者技术路线的发展脉络。instructed LM,它是需要对pre-trained LLM进行finetune的,在这之前也有一种技术叫做prompt engineering,它是一种给大模型指令输入的手段,通过调整给大模型的输入,从而使得大模型能够返回更好的输出,解决我们的问题。也有更好的解释引用自blog
Prompt Engineering, also known as In-Context Prompting, refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics
prompt engineering得益于LLM拥有zero-shot learning和few-shot learning的两种prompt 模型的方法的发展。它更多的来源于经验。
prompt engineering领域也出现了非常多的文章,就正如blog里的观点一样,我同样觉得有一些文章只需要很少的文字就能讲明白它提出的方法是什么,但还是花了很多的篇幅,一个通用的benchmark才是我们需要的,现在有的只是一些零零碎碎的方法论。prompt engineering不是我的关注重点,它受制于很多因素的影响,比如如果你使用的是GPT-3模型来开展你的任务或者搭建你的application,你可能会因为输入过多的文字而超出limit,而且GPT可是按照字符数收费的,所以可能会比较贵。
那么除了使用prompt engineering的方式来让LLM输出能让我们满意的结果,另外一种方式是fine-tune整个LLM,直接让它在特定的数据集上调整参数(整体调整或者局部调整,比如Lora,prefix-tuning)或者使用增强学习训练一个打分模型,这也属于fine-tune的一个大分支。
2013年的综述文章A Survey of Large Language Models 在第五章介绍了详细的adaptation tuning of LLMs的方法,也就是我一个pretrain好的LLM,如何让它在不同的任务上得到更好的泛化能力,这时候就要tuning LLM。作者介绍其中有两种方法,一个是instruction Tuning,第二个是alignment tuning。后者就是利用增强学习让模型从人类的反馈中去改进自己生成的文本,InstructGPT采用了这种方法。第一种会稍微复杂一点,但原理很简单,就是创造一系列的instruction和问答对,让LLM在这些新instruction上重新finetune,loss为sequence-to-sequence的loss。
[My personal spicy take] 这里这篇综述我觉得写的不完整,有点误导读者。这篇综述第五章只介绍了adaptation tuning模型中的两种,但在instruction tuning出现之前,还有不少技术能够帮助我们“further adapt LLM according to specific goals”. 不仅如此,这篇综述也没有很好的解释instruction tuning为什么就能帮助我们在不同任务上有了performance的提高。所以我就想写一篇博客来记录如果我们拥有了一个pretrained的大模型,我们可以有什么样的做法来使得大模型在特定的任务上为我们所用。详见另一篇博客“Adaptation Tuning of LLMs”
在接触羊驼模型后,我一直有一个疑问,为什么instruction finetuned模型performance有了提高,或者说它在什么样的任务上有了提高?这个问题一直困扰我,直到我看到了google家的Finetuned Language Models Are Zero-Shot Learners.instruction tuning这种finetune方式的提出是为了improve zero-shot performance on unseen tasks,具体一点就是在一些任务上比如阅读归纳,question answering和语言推理上,研究者发现GPT3的zero-shot learning比few-shot 能力差很多,作者说一个潜在的原因是因为如果没有一些context给到模型的话,模型在面对跟pretrain时候数据相差很大的prompt时候会很困难,说直白点,就是没有例子给它参考了,就不会做题了。instruction tuning这种方式就提供了一种非常简单的方式,它在好多个task上finetune这个模型,这里每一个task的数据组织形式跟原来不一样了,现在被组织成了(instruction,[input],output)的形式。finetune完之后的模型在unseen task上做evaluation,研究者发现被instruction finetune之后的模型比原来的模型在同一任务上的zero-shot能力大大提升:
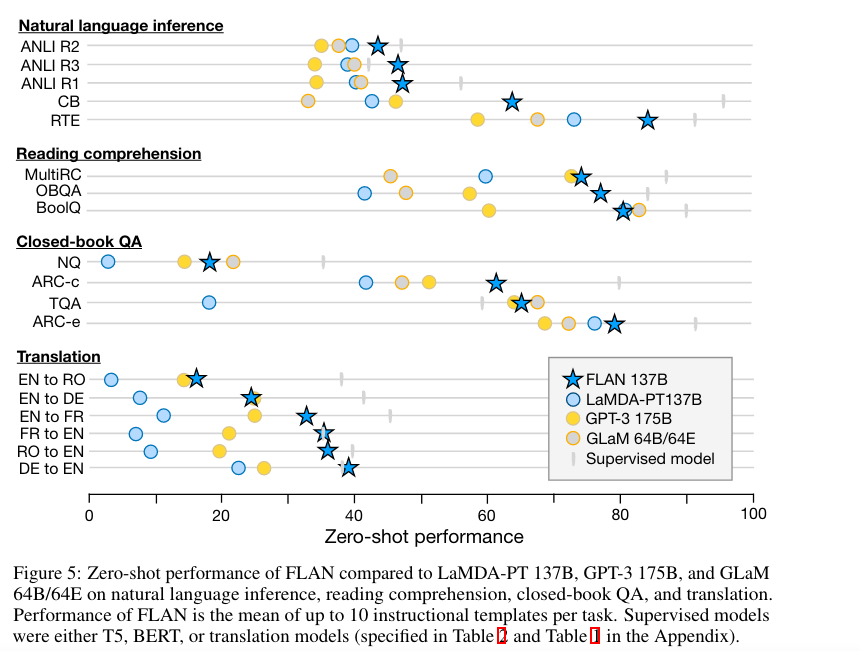
instruction tuning
想要做到instruction tuning有两个前提条件:1. 你有一个pretrained的模型 2. 有很多instructions。首先第一个条件可以看看市面上有哪些模型是已经开源了,参考A Survey of Large Language Models3.1的整理,2023年斯坦福的羊驼模型是基于meta的LLaMA,所以目前github上出现了很多用LLaMA为LLM,在上面做instruction tuning工作的。
那第一个问题解决了,起码我们有开源的LLM可以load到本地来使用,感谢facebook的开源。第二个问题如何产生很多的instructions,斯坦福的羊驼模型Alpaca采用的是下面文章介绍的方法,省时省力,花费上不超过600美金。当然也有其他的一些产生instruction的方法,详细可以参考A Survey of Large Language Models ,其中作者介绍了一系列可以从现有数据集生成instruction的方法,这些方法应该也是低成本快速产生instruction的方法。
Self-instruct: Aligning Language Model with Self Generated Instructions 这篇文章介绍了一种self generated instructions的方法,简单说就是让LLM自己生成人类的问题的答案,然后将这些instructions 重新来fine-tune我们的LLM。这样做的一个前提条件是:1. Large “instruction-tuned” language models (finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks. 2. 产生instruction data非常的耗时,原来都是采用Human written的方式。具体步骤是:
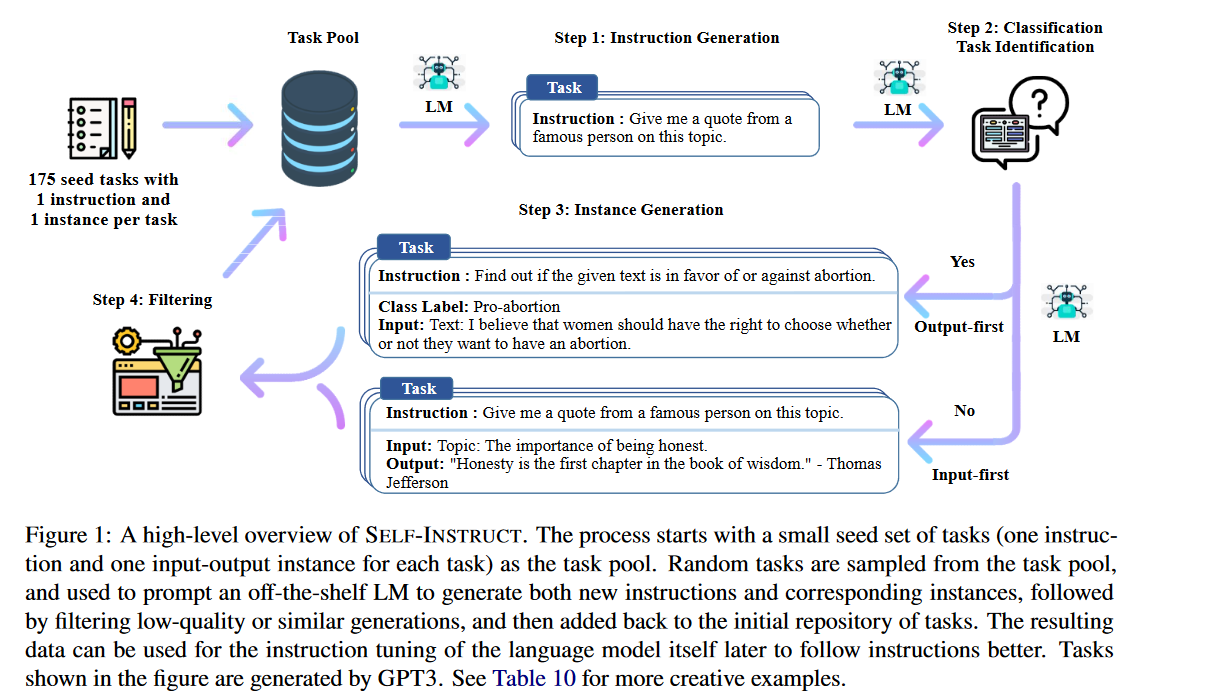
作者首先使用175个手工写的instructions作为seed set,利用这175个instructions用LLM再次生成更多的instructions,将这些instructions再次输入到LLM中我们就得到了很多input-output pair。这些input-output pair将会用来做instruction tuning. 作者使用的LLM是GPT-3. 最终得到了52k个instructions,以及82k个input-output pair。
Instruction generation
用bootstrap的方式,以人工产生的instruction为基础,用GPT来自己生成更多的"new and novel"instruction。
自Alpaca之后,国内的一些团队也仿照斯坦福的这种模型,做了一些自己的LLM,例如https://github.com/LC1332/Chinese-alpaca-lora,instruction来自用GPT翻译的斯坦福产生的52k的instruction的数据,它基于的模型aplaca-lora,lora的全称是Low-rank adaptation,作者说自己"reproducing the Stanford Alpaca results using low-rank adaptation (LoRA).",并且训练好的instructed model提供的文本质量可以和text-davinci-003(GPT-3)媲美。不太了解这个LoRA,有兴趣的可以读原文:https://arxiv.org/pdf/2106.09685.pdf。
看了Alpaca的blog,我发现斯坦福在evaluation阶段是将alpaca的结果和gpt3来进行比较的,由此也引发了我的思考,就是我们如何去衡量一个LLM的performance。刚上文的review的第七章很好的解答了我的疑惑,包括一系列的基本评测任务以及高级的评测任务。当然作者在7.3也给出了一些公开的全面的benchmarks,而且是用的比较多的,其中有MMLU,BIG-bench,HELM,这些benchmark内都包含了很多个任务,可以综合评测一个LLM的performance。
stanford alpaca
这是2023年斯坦福开源的一款基于meta的LLaMA的大语言模型,名字叫羊驼,只有7个billion的参数。属于instruction tuning的一个标杆。里面用了两个比较新的技术,第一个是上文提到的self-instruct,就是让GPT或者市面上的LLM在我们人工产生的种子instruction上去产生一系列更多的instruction,包括配套每一个instruction的input和output。斯坦福将这部分用GPT-3.5(text-davinci-003)产生的instruction数据慷慨开源,见github。不仅如此斯坦福还给出了产生这些instructions的代码,可谓是非常nice了,方便大家上手学习。
我比较关注用这些instructions数据如何finetune大模型LLaMA的过程,这里权当自己复现以及阅读斯坦福代码时候的记录。首先我本来是想在meta的LLaMA的7B开源模型上做实验,但发现想获取meta的weights需要提前申请,详细可参考huggingface的transformer页面。
斯坦福的代码仓库可以在github找到。