decoding strategy in NG tasks
在Neural Language Generation的任务中,如何在每一个时间步产生一个token称为decoding method.最常见的decoding方法就是用softmax激活函数计算概率分布之后,将概率最大的那个token列为当前的预测值(most likely string)。这种argmax的方式在machine translation等non-open-ended的任务中表现还可以,但是如果是在纯粹的开放性的任务中,比如写一首诗歌。这种方式会造成重复性的输出,并且输出的句子有时候连续性也比较差。
这时候很多研究工作就对decoding strategic展开了研究,比如beam search,基本原理很简单,就是从取概率排名前k个token作为当前预测值。但是这还是会有一个问题,就是当我们概率分布均衡的时候,这个方法可以,但如果概率分布不均衡,也就是softmax计算出来的概率值只有几个token的概率比较大,其他概率都非常小,比如零点几,那这个时候其实我们不太需要考虑k个单词,只需要考虑概率比较大的那些tokens就够了。
Top-p(Nucleus Sampling)
所以这时候就有人提出了Top-p(nucleus) sampling的方法The Curious Case of Neural Text Degeneration
具体做法就是维护一个动态的k值,这个k值随着softmax的输出概率分布决定,
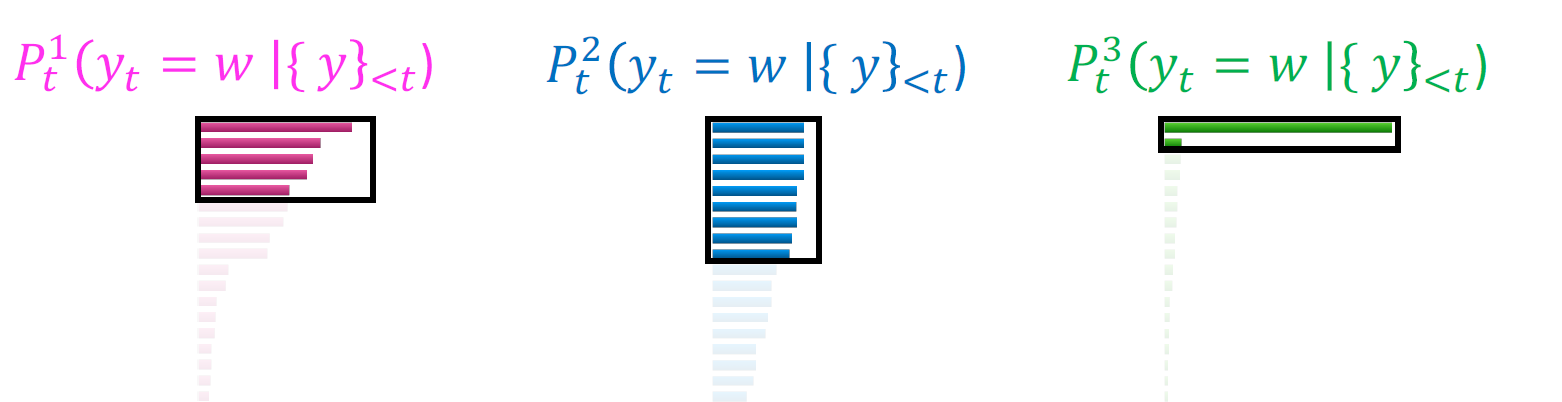
作者的思路就是当概率分布比较flat的时候,我们应该把sample的池子定的大一点。但是当概率分布比较陡峭,也就是上图中的第三种情况时,我们就需要把这个sample的池子变得小一点。具体是如何操作的呢?
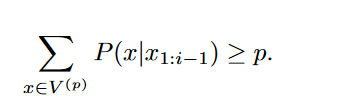

看公式可能会比较复杂,具体做法就是提前预设一个阈值p,然后对于某个时间步的概率分布P,我们寻找一个最小的top-p的一个token池子,这个池子里所有的token的概率值加起来要大于p,注意这里是找一个smallest set,也就是我们在找这个token池子时,从概率最高的token往下捋,一直到概率和大于p。找到这个池子之后,我们将原来经过softmax函数计算之后的概率分布按照上图中(3)的公式重新计算得出一个新的概率分布。最终我们得到的概率分布不属于我们之前找的token池子里的token的概率全部置为0,至于在这个token池子里的token的概率值会除以这个池子里所有token概率值的和。然后我们从这个分布中去sample我们的预测token。
Sampling with Temperature
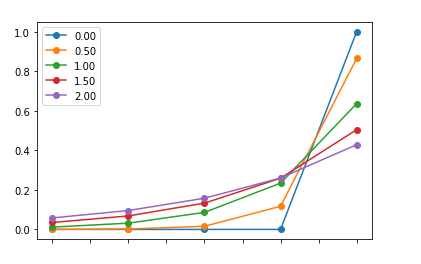
Temperature这个概念在GPT中也有,不同的温度值,你会得到不同的结果。温度值越低,它会对自己的输出结果更自信,而温度值越高,它会降低模型的确信值,也就会返回更多的结果给你。Blog对上面提到的The Curious Case of Neural Text Degeneration文章进行了解答,但我发现有一点和paper中不一样的是:
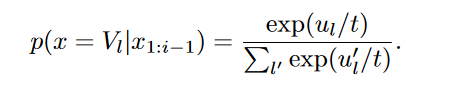
temperature值t并不是取值是[0,1),stanford224n的课件以及博客里对t的取值是可以大于1的:

在博客中我们可以看到作者对于t值大于1和小于1画出的图的区别: