Adaptation Tuning of LLMs
让LLM适配specific的下游任务,两条线:1. 在prompt engineering上下功夫 2. Fine-tune LLM. 其实这两条线并不分家,中间也有一些技术是有overlap的。prompt engineering并不只是手动设计prompt让LLM返回更好的结果,使得其在下游任务中得以使用,一些研究并不想自己手动设计prompt,那就产生了很多自动产生prompt的方式。刘鹏飞博士的review文章Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing将这些技术统一到一个体系里来,分类方式也比较清晰:
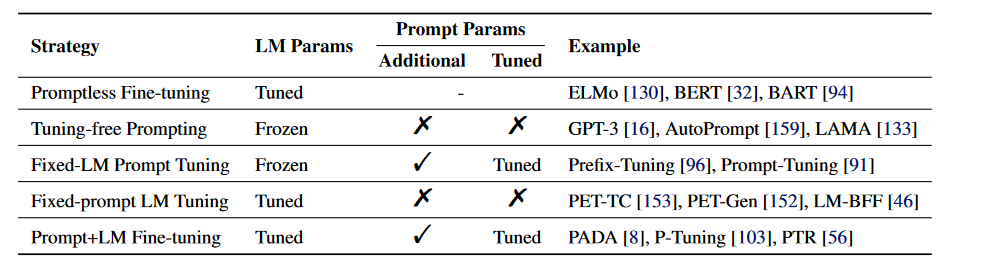
Full Fine-tune(Promptless Finetune)
Bert就是一个典型的应用,将模型在一个很大的语料库上pretrain之后,再在一些任务的数据集上对模型参数进行调整。注意这里模型的所有参数都会进行调整。
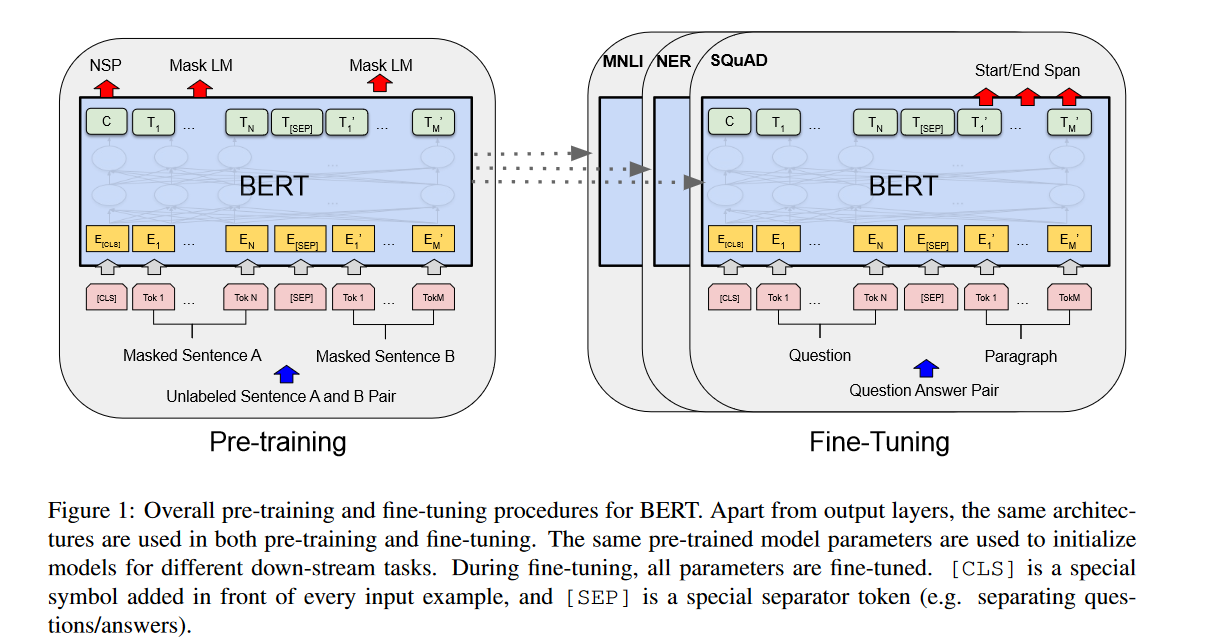
对所有模型参数调整就带来很多问题:
- 要维护每一个task上的模型,有一些模型的参数量都是亿级别的,这对存储是一个考验
- finetune所有参数就需要数据集达到一定的数量级,这在特定领域不一定是可以达到的;如果没有很多数据,有可能finetune完之后还会引起perfomance的下降或者过拟合。
- 计算资源的限制
More Efficient Ways of Tuning
或许有更合适的tuning方式,less overfitting and more efficient finetuning and inference
Prefix-Tuning
Prefix-Tuning: Optimizing Continuous Prompts for Generation
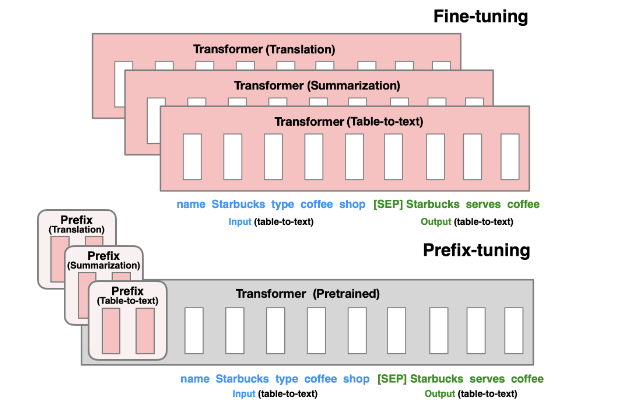
一开始理解prefix tuning其实是从“如果不调整所有参数,那么是不是可以调整部分参数”来思考这个模型的。但是看了原文之后会发现作者的思考路径其实有点不太一样。paper中说
Prefix-tuning draws inspiration from prompting, allowing subsequent tokens to attend to this prefix as if it were “virtual tokens”
lilian的博客对于这个也解释的蛮有意思:
Prompt is a sequence of prefix tokens that increase the probability of getting desired output given input. Therefore we can treat them as trainable parameters and optimize them directly on the embedding space via gradient descent, such as AutoPrompt (Shin et al., 2020, Prefix-Tuning (Li & Liang (2021)), P-tuning (Liu et al. 2021) and Prompt-Tuning (Lester et al. 2021). This section in my “Controllable Neural Text Generation” post has a good coverage of them. The trend from AutoPrompt to Prompt-Tuning is that the setup gets gradually simplified.
也就是既然我们发现in-context learning是可以促进大语言模型解决特定问题(因为我们让LLM以更高的概率输出我们想要的结果了),那么是不是可以可以把这一部分信息编码进模型参数里,从而在特定地数据集上单独训练这些参数。
所以研究者也想了一些办法如何以最小的成本为特定的任务增加一些参数,fix住预训练模型的大部分参数,而去finetune给每一个任务增加的那一部分参数。其中adapter-tuning就是一种。