训练一个information retrival
近期中文大语言模型出现了好多产品,独领风骚的chatglm-6B确实表现很不错,所以大家就纷纷下场想做一个自己领域的大语言模型,最近看到一篇Lawyer LLaMA Technical Report,作者基于llama模型做了一个法律的语言模型。我觉得这篇文章值得想在垂直领域做语言模型的研究者参考,特别是它所采取的路径:
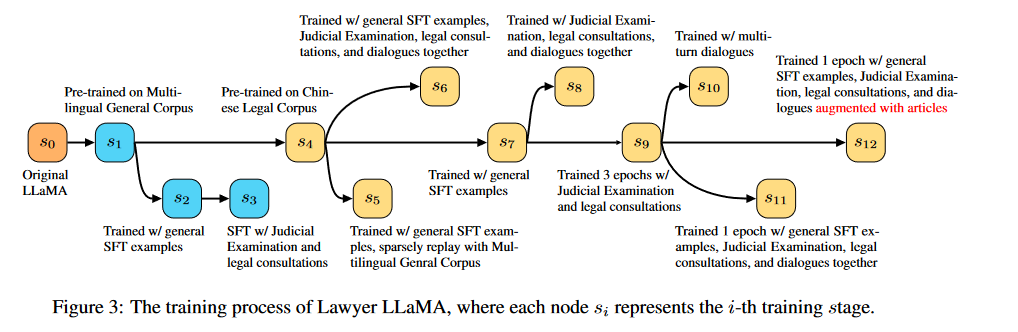
也有博客粗略介绍了这篇文章。
我重点关注的是这个工作里的信息抽取:
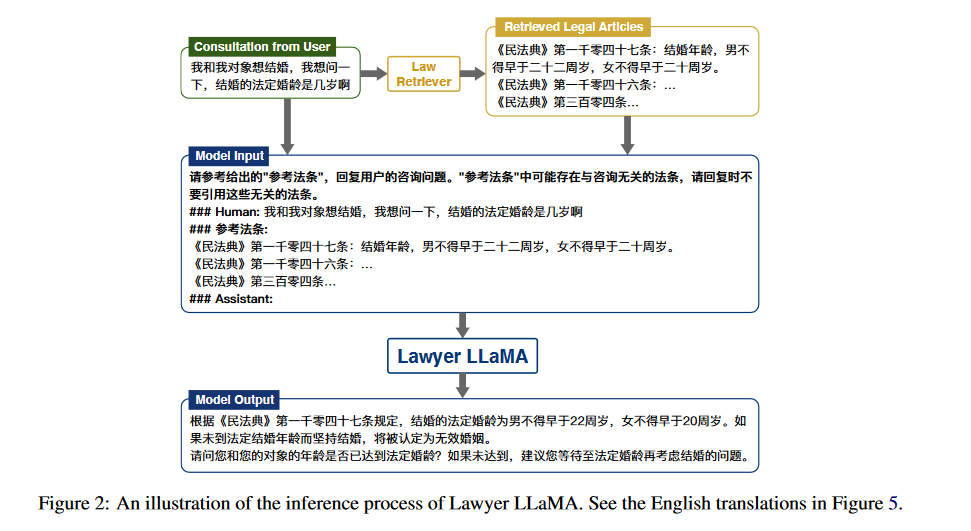
思路大概就是和斯坦福的dsp一个思路,用户问一个问题,第一种方式就是直接把这个问题抛给llm,让它去回答,第二种就是在把问题抛给llm之前先过一道retrival模型,这个模型会抽取一些和回答这个问题相关的一些context,将这些context加入prompt中,然后再抛给llm。这有一个专门的名词,在Demonstrate-Search-Predict: Composing retrieval and language models for knowledge-intensive NLP 中有所介绍: retrieve-then-read。有兴趣的可以再看一下斯坦福在做这部分工作时出的notebook介绍,看完你就知道为啥要retrieve一些context加入到prompt中去。
可惜的是laywer llama这篇文章并没有详细的介绍它的retrieve咋做的,文章中也是一笔带过,数据规模包括组织形式一概没说。我主要是参考斯坦福的dsp这框架中retrieve的实现,它是基于ColBERTv2做的抽取模块,但其实colbert预训练的模型是在微软的msmarco数据集上训练的,也就是没有中文,那必然对中文的适配度应该就不太行,所以我就想找找有咩有好心的博主写过自己用colbert在自己组织的语料库上训练的过程,发现没有,所以这就是我写这篇文章的动机啦,希望能给后面想用自己组建的数据集训练一个colbert做信息抽取的童鞋一点参考。
以下的内容参考colbert github
数据组织
模型使用
用官方训练好的checkpoints
参考https://github.com/stanford-futuredata/ColBERT/blob/main/docs/intro.ipynb
里面的输就LoTTE的url已经失效了,包括checkpoints的下载地址。可以到hugging face的仓库找
- colbertv2.0 checkpoints : https://huggingface.co/colbert-ir/colbertv2.0/tree/main
- lotte 数据集地址: https://huggingface.co/datasets/colbertv2/lotte/tree/main
注意上面这个lotte的数据集的组织方式和colbert官方github仓库里的介绍不一样,这一点上colbert2这个代码仓库的维护做的蛮糟糕的,比羊驼可差远了。
1 | import os |
ok 偶然看到官方仓库昨天更新了intro的notebook,我看到里面下载数据集的仓库变化了,然后导入包的时候也写得更清晰了,加了条件:https://github.com/stanford-futuredata/ColBERT/blob/main/docs/intro2new.ipynb