llm赋能的全自动Agents
这篇文章来源于liianwen的blog,初看这篇博客时感觉太多新技术看不懂,再者今天突然看到新智元公众号发了一篇文章,乍一看特别熟悉,对比了下确实是完全照搬翻译,让人读起来一头雾水,不仅如此,跟原博客相比缺失了很多内容。
强烈建议先食用blog, 很通俗的讲解了LLM发展到现在成为Agents的原因,这里引用博客中的一句话:
Recent months have seen the emergence of a powerful new trend in which large language models are augmented to become “agents”—software entities capable of performing tasks on their own, ultimately in the service of a goal, rather than simply responding to queries from human users
也就是研究人员已经不满足于让LLM仅仅是根据query回答问题,更希望它能帮我们完成一些任务,成为我们工作生活的“助手”,就好像你有一个秘书一样,你让他去定一个航班,秘书可能会进行一系列的操作,比如他要考量你的时间安排,还要考虑航班的情况等等,你最终就是拿到了秘书给你的机票,但其实秘书在中间做了超级多事情。那我们现在就希望能把LLM培养成这样的角色,他不仅能接受命令还能自己做决策,然后把任务完成了。刚刚提到的博客里还讲了一个购买车的例子。
那我们知道我们的终极目标是要实现一个高级别的私人助理,那么实现这个目标需要哪些技术呢,这时候才到了lilian wen的这篇博客部分。引言就是现在一些agents的雏形比如autoGPT, GPT-engineer和BabyAGI出现了。
lilian的博客认为agents是以LLM作为大脑,配置三个主要的components:planing,memory和tool。Planning主要是将复杂任务拆分,不仅如此它还要负责自我反省,吸取以往错误的教训,从而能够产生更好的结果。

Memory包含短期记忆和长期记忆,前者可以理解成in-context learning中应用的记忆,后者主要是应用外部的向量数据库或者本地知识库抽取的知识。Tool就是agent可以拥有调用各个外部API的能力,就像你的武器库一样,不同的武器适合不同的作战场景,这些API就可以弥补预训练完的模型所欠缺的能力,比如对于当下实时信息的获取。
Component 1: Planning
拆解任务有两种主流办法:1. CoT chain of thought 2. Tree of Thoughts
前者被讲烂了,后者是对CoT的扩展,将任务拆解成一个子任务树,然后采用宽度优先搜索或者广度优先搜索的方式去决定接下去先解决哪个子任务。
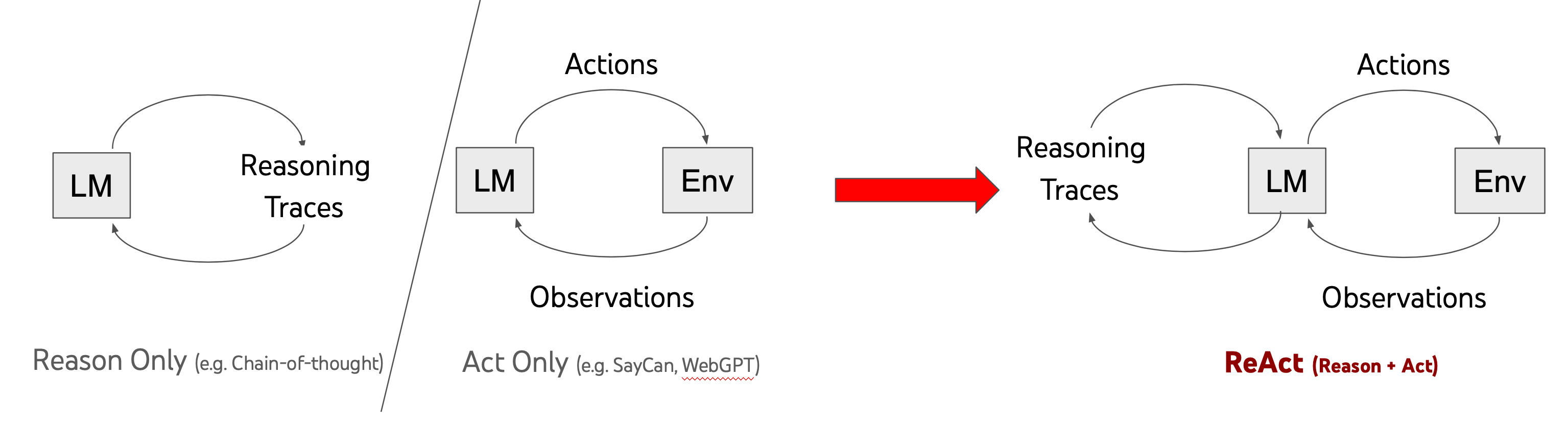
planning这个子模块还有一个更重要的功能就是自我反思,人都是需要从错误中进步的,大语言模型也是一样。思想有点类似于增强学习。首先讲到的是ReAct,
说实话lilian博客里写的这一段我没看懂,所以还是找原文paper来看了下。

从上面的例子就可以理解作者提出的办法就是将thought和action结合起来了,也就是单纯的思考比如chain of thought并不能很好的回答问题,受制于预训练模型自己模型内存储的知识,而如果只有action呢?就是不停的去搜索,如果搜索不到正确的答案那也是白搭。其实我理解就是作者提出我们要做一个通用的人工智能,你要告诉他在行动的时候也要思考,思考清楚之后再去考虑下一步已经采取什么样的行动,同时每一次行动也会从环境中得到反馈,比如作者举的第二个例子,你去countertop(台面)的时候,你看到了苹果,面包,胡椒粉瓶子和一个花瓶,既然我们要把胡椒粉瓶子放到抽屉里,那就可以拿走胡椒粉瓶子啦!其实这也好理解,一个优秀的人其实也是要边做边思考的,所以就形成了作者提出的prompt新范式:
1 | Thought: ... |