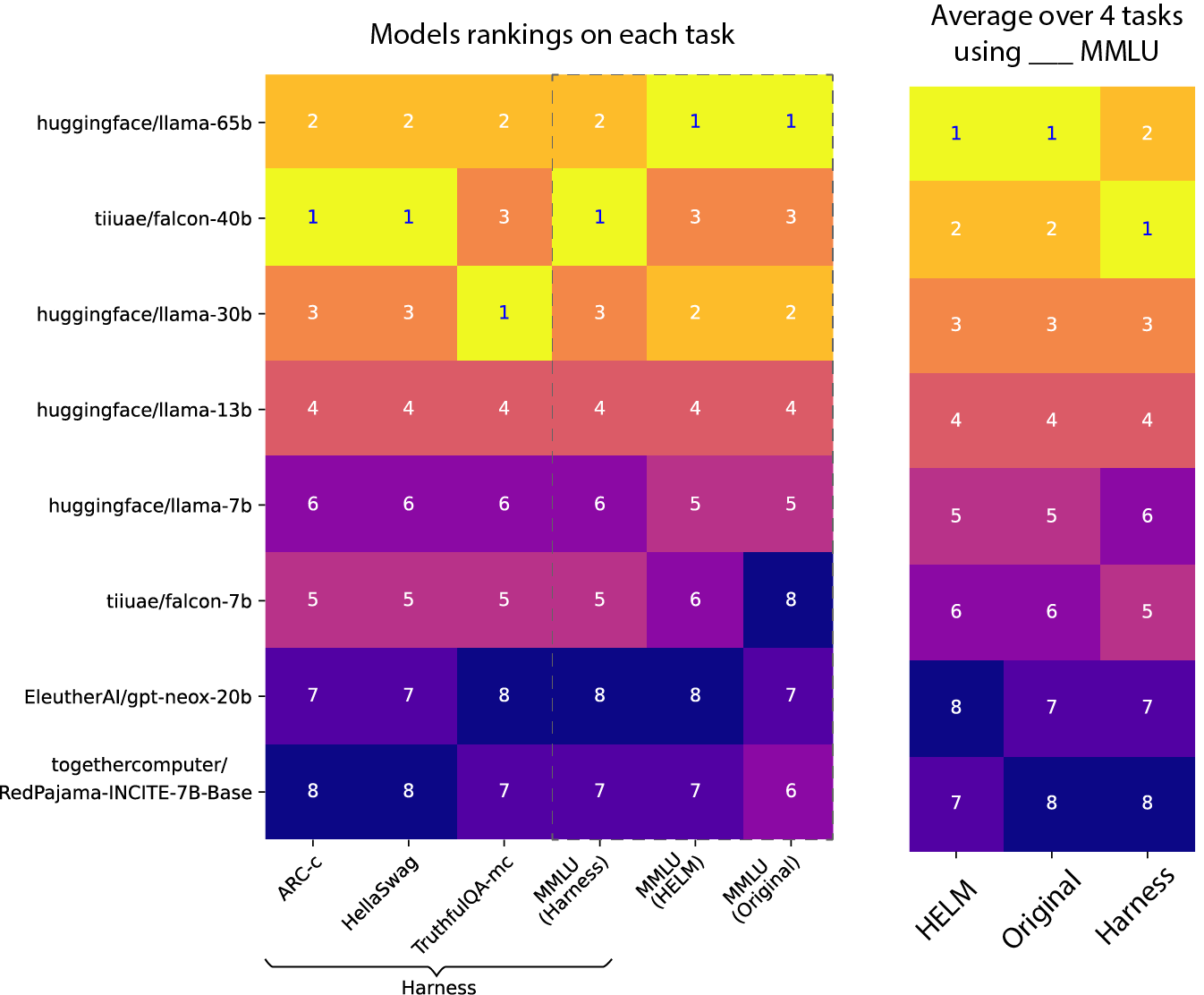
MMLU (Massive Multitask Language
Understanding) is a new benchmark designed to measure knowledge
acquired during pretraining by evaluating models exclusively in
zero-shot and few-shot settings.
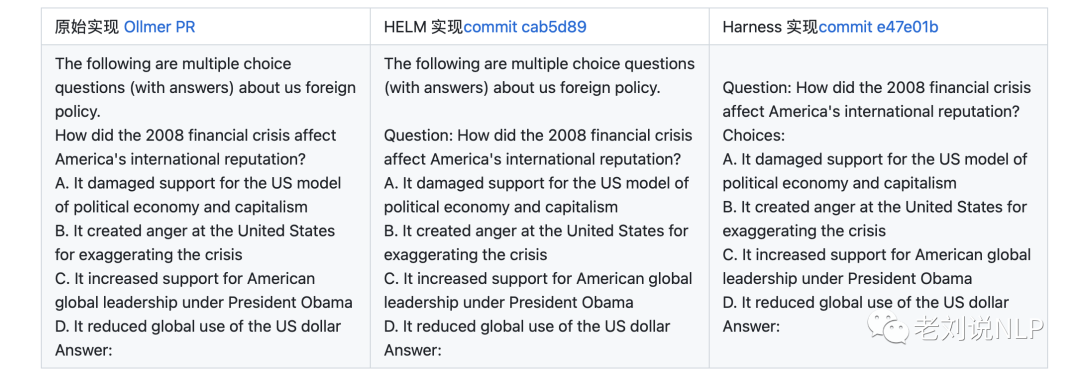
关于如何使用这个benchmark,参考MMLU原始实现,作者写的是用chatgpt来产生答案,prompt为:prompt = "The following are multiple choice questions (with answers) about {}.\n\n".format(format_subject(subject))
data = [ "A multilayer perceptron (MLP) is a class of feedforward artificial neural network (ANN)", "The term MLP is used ambiguously, sometimes loosely to any feedforward ANN, sometimes strictly to refer to networks composed of multiple layers of perceptrons (with threshold activation); see § Terminology", 'Multilayer perceptrons are sometimes colloquially referred to as "vanilla" neural networks, especially when they have a single hidden layer.[1]', "An MLP consists of at least three layers of nodes: an input layer, a hidden layer and an output layer. Except for the input nodes, each node is a neuron that uses a nonlinear activation function.", ] model = transformers.GPT2LMHeadModel.from_pretrained("gpt2") tok = transformers.GPT2Tokenizer.from_pretrained("gpt2") tgs = [] for dat in data: random.seed(dat) # print(model(tok.encode(dat, return_tensors="pt"))[0][0]) toks = tok.encode(dat, return_tensors="pt") ind = random.randrange(len(toks[0]) - 1) logits = F.log_softmax(model(toks)[0], dim=-1)[:, :-1] # [batch, seq, vocab] res = torch.gather(logits, 2, toks[:, 1:].unsqueeze(-1)).squeeze(-1)[0] tgs.append(float(res[ind:].sum()))