LLM大模型推理加速
最近框架vLLM在LLaMA-13B以及7B模型上的推理速度相比较Tranformers有了质的提升。之前写过一篇大模型量化技术的文章,量化技术算是大模型出来初期大家使用的普遍比较多的方法之一,这里强调一点,我这里所说的模型加速是指在推理阶段我们让模型运行的更快,而且返回的结果要和原来的大参数模型差不多。这里重点强调的原因是我在看一些资料的时候发现有不少博客分享的是在模型训练阶段或者finetune阶段如何让模型训练的更快,这里就涉及到efficient finetuning的技术(p-tuning, prefix-tuning等),我这篇博客只关注模型训练完成之后如何在推理阶段让它更快,在同样时间内处理更多sequence(吞吐量througout),显存占用更低。大模型推理加速技术为什么这么受关注还是因为想在一些消费级别显卡上部署一个大模型为用户所用,而不是仅仅停留在实验室阶段。
我在看这个topic下的文章的时候,发现往往一些方法提出来有一些是减少了显存占用,有一些是提高了吞吐量(跟减少latency一回事),所以具体在实现时应用哪个办法加速你的模型推理还要根据实际情况去对比分析,或者你每个方法都尝试一下也行。当然又一些方法集成地很好,比如量化模型中的GPQT已经集成进transformers库,用起来很方便。如果碰到一些很复杂的,比如prune“剪枝”就有点难以快速验证。
vLLM 暂时还没有文章发出来,我在谷歌搜寻有没有review介绍大模型加速文章的时候也没找到很新的文章,不过找到了一篇微软在23年发布的LLMA, 我本来觉得思想类似,但是后来仔细看了下文章发现并不是一回事,我觉得文章标题有点误导人,起的太大了,本质上文章其实就是发现了decoding时候生成的句子和之前的句子有一部分的文字重叠,所以作者考虑这部分重叠内容其实不需要让模型再去decoding了,那就想了个办法,在decoding的时候把前面一步的结果保存下来,比较当前步骤和前一步骤token的差距,差距小的就不再进行计算了
一点不成熟的想法:这个文章思路可取,但创造力有限。
不过它在introduction章节介绍了四种比较通用的加速方法:quantization, pruning, compression and distillation,同样的分类也可以在A Comprehensive Survey on Model Quantization for Deep Neural Networks文章中找到, 不过两者介绍的有一点点的不同:
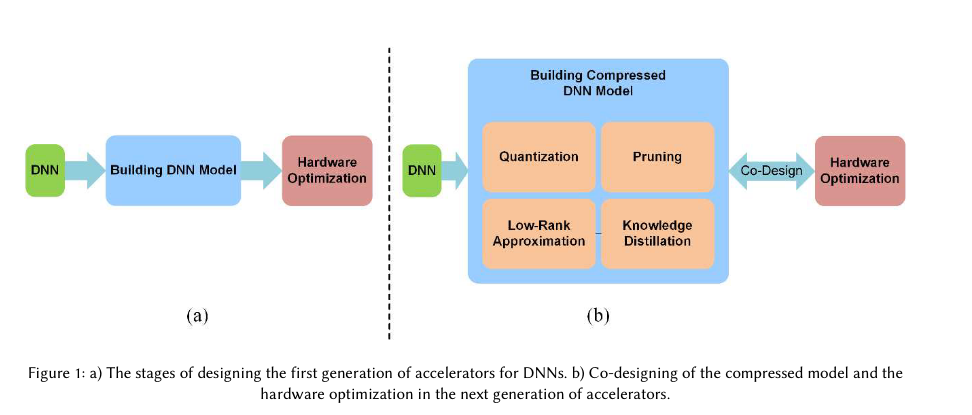
Survey将四种技术统一包含在了模型压缩里。我觉得review里这种分类比较合理,因为微软这篇文章compression引用的文章是
Bert-of-theseus: Compressing bert by progressive module replacing, compression应该是一种统称。后面我看到知乎有一篇文章更详细的介绍了大模型的推理优化技术,它这个分类也符合我的理解,模型压缩(model compression)里包含模型量化,pruning,low-rank approximation和知识蒸馏这些技术。而且知乎这篇文章的分类也符合survey里的介绍:
In designing accelerators, researchers concentrate on network compression, parallel processing, and optimizing memory transfers for processing speed-up.
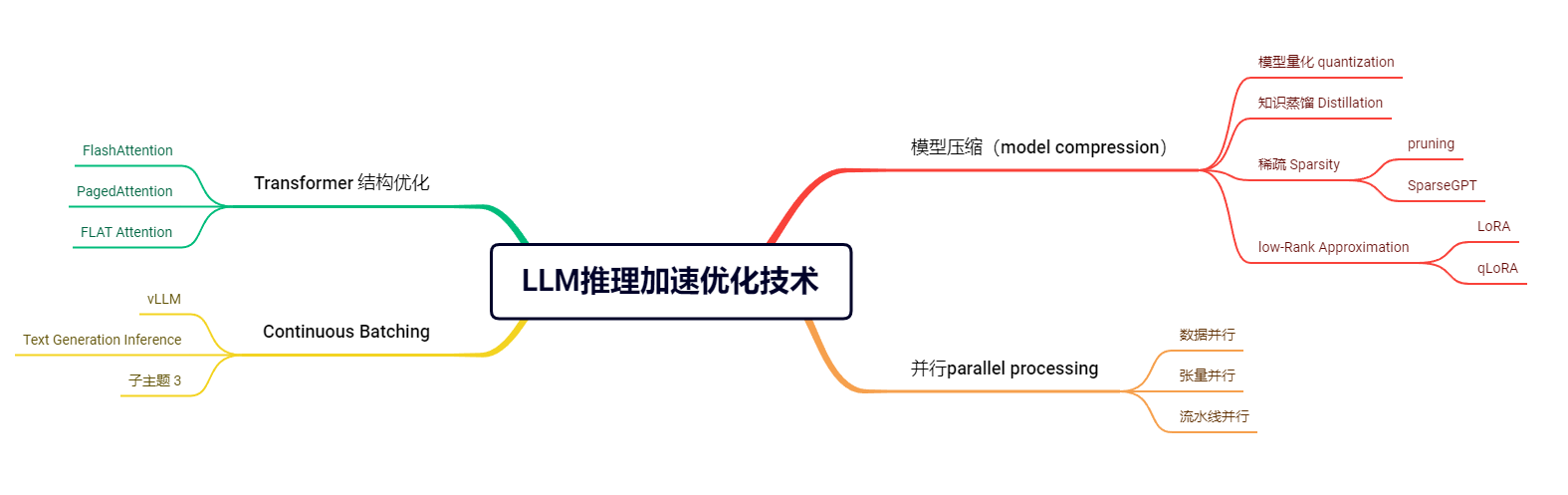
我这里做个思维导图总结一下:
题外话,根据LLMA文章的意思,它提出的这种帮助reduce the serving cost的方式不属于上述任意一类,它认为以transformer为基础的生成模型,推理阶段主要消耗的时间瓶颈在autoregressive decoding。这里贴原文便于理解
While there are general methodologies that help reduce the serving cost of LLMs such as quantization(Dettmers & Zettlemoyer, 2023), pruning (Frantar & Alistarh, 2023), compression (Xu et al., 2020) and distillation (Wang et al., 2020), the inference efficiency bottleneck of these transformer-based generative models (e.g., GPT) is mainly associated with autoregressive decoding: at test time, output tokens must be decoded (sequentially) one by one, which poses significant challenges for the LLMs to be deployed at scale. 这里补充介绍一下AI模型中精度,你会在各种场合下碰到FP32,FP16,int8,int4等名词。
32-bit:也称全精度(Single precision),fp32,
采用32位(4字节)来对数据进行编码。能够表达的数据动态区间是 \[
1.4 * 10^{-45} - 1.7 * 10 ^ {38}
\]

16-bit:半精度(half precision),fp16,
能够表达的数据动态区间是 \[
6 * 10^{-8} - 65504
\]

BF-16: 也称为半精度,可以表达比FP16更大的数,但是精度比fp16差
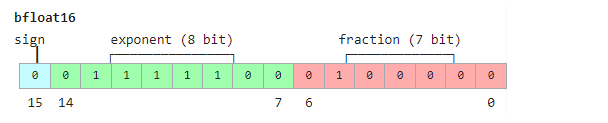
int8,int4顾名思义就是 8bit和4个bit来表示数字,int8的表达数值范围是
-128~127 why,无符号范围是0~255,int4的表达数值范围是-8~7。注意这里的计算方式和上面的浮点数可不一样,上面的浮点数中的8bits的exponent是指数表达,所以将指数那一部分的表达加和之后还要取2的指数,见具体计算.
再详细一点的介绍见hugging
face 博客
模型压缩 model compression
Quatization 量化
参考文献
- A Comprehensive Survey on Model Quantization for Deep Neural Networks
- https://huggingface.co/docs/transformers/main_classes/quantization#autogptq-integration huggingface的document,其中放在最上面的就是GPTQ
- 大语言模型的模型量化(INT8/INT4)技术
讲解了
LLM.int8() - LLM.int8() and Emergent Features
模型的量化可以分为两种方式:
- post-training quantization 模型训练好之后,将模型的参数们降低精度
- quantization-aware Training 在模型训练的过程中使用量化的方式,优点是比前者performance要好,但是需要更多的计算资源去训练
量化顾名思义要把原来用高精度表达的值映射到一个低精度的空间,目标呢就是让模型的performance不能有很大的降低。那如何映射和对哪一些值进行映射,这两个方向是现在量化方法的主攻方向。
很典型的LLM.int8()算法,不是大刀阔斧地对所有值一次性量化,也不是把矩阵中所有值一起量化,而是先找出那些离群值,然后对这些离群值再按照居正中行列来进行量化:
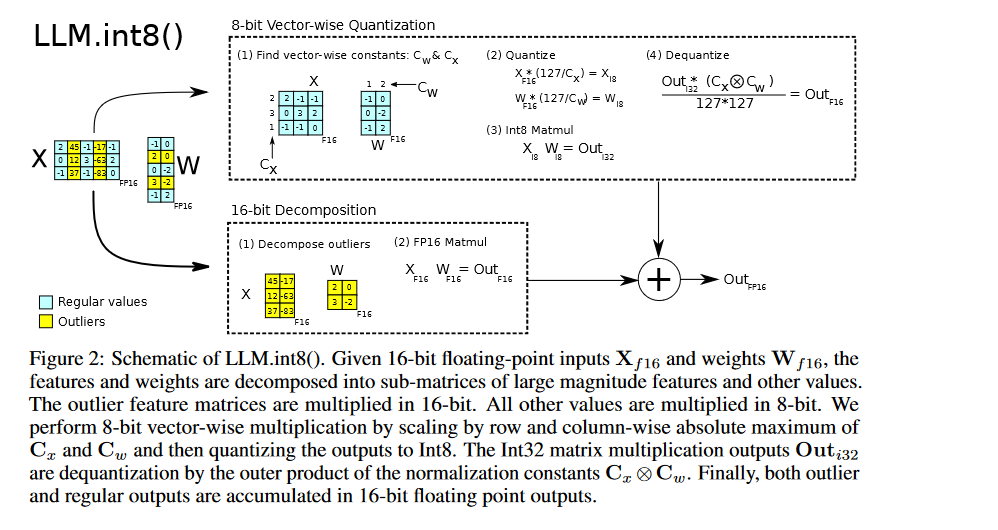
最重要的是上面那一部分。计算拆解见大规模 Transformer 模型 8 比特矩阵乘简介
GPTQ
读者可以自行阅读GPTQ的原文来了解它具体是如何做的,我喜欢找一些其他的文章来看别的作者是如何介绍自己的同行作品的,比如下面的这篇文章SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models 的第六章节related work里这样比较自己的smoothQuant和其他的量化模型方法的:
GPTQ (Frantar et al., 2022) applies quantization only to weights but not activations. GPTQ这种方法只对weights做了量化,并没有对激活值做量化(我个人认为虽然这是事实,但有点硬凹的意思,因为对activations做量化映射并不会加速很多)
LLM.int8() uses mixed int8/fp16 decomposition to address the activation outliers. However, such implementation leads to large latency overhead, which can be even slower than FP16 inference. 意思是LLM.int8()这种方法只是减少了显存占用,并没有减少推理延迟,说白了就是慢,runtime没提高
Sparsity
low-Rank Approximation
Lora
用lora的方式替换全参数微调大模型已经成为好多研究者的选择,一个是它的确有效的降低了训练参数的比例,第二个很大的原因是它的performance还不错,也就是只训练低秩的那些参数矩阵完全可以得到一个高质量的模型.
We propose Low-Rank Adaptation, or LoRA, which freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks
从文章的介绍可以看出,它主要是应用于transformer架构中的layer中,这个layer包含self-attention,也包含MLP。只要有矩阵乘的地方都可以用lora。
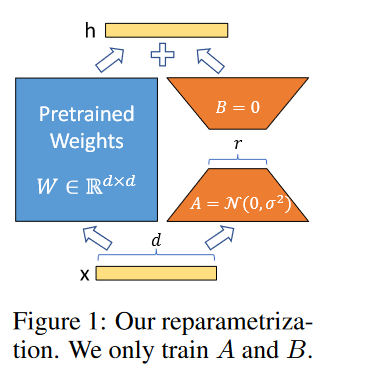
具体的在transformer中如何使用呢?我们知道transformer架构中涉及矩阵运算的地方:
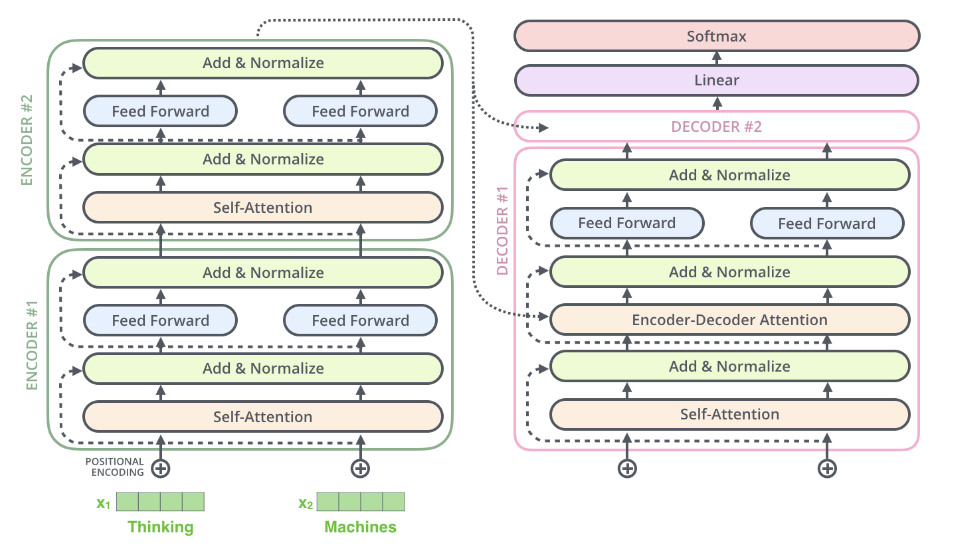
在上图中的self-attention中涉及四个weights矩阵:(Wq, Wk, Wv, Wo)。在feed-forward(lora原文中叫MLP,我觉得原因在于这里是有两个线性变换的),具体看attention is all you need 原文:

所以每一个encoder的layer都有6个weights矩阵可以实施lora。lora的作者仅仅对attention weights做了lora,更简化的只是对其中的Wq和Wv做了lora变换。实现上由于现在有了peft库,只是几句话就能实现对这两个矩阵进行lora:
1 | def create_peft_config(model): |
Knowledge Distillation
知识蒸馏出现的比较早,一开始也是在Bert上流行起来的。在LLM这种非常多参数的模型上用的不多。
这里罗列我看的对我理解很有帮助的文章:
- Natural Language Processing with Transformers, Revised Edition 第八章“Making models smaller via Knowledge Distillation” 很详细的介绍了loss的计算(只是蒸馏的核心点)
- lilian wen blog
Continuous Batching
参考文献:
vLLM
vllm这个包本质上是将显存GPU高效利用了(PagedAttention技术),还有上面提到的LLMA. 不过它们的思路其实大同小异,本质上是为了解决transformer的decoder在文本生成时自回归结构带来的无法并发的开销。推荐阅读为什么现在大家都在用 MQA 和 GQA?
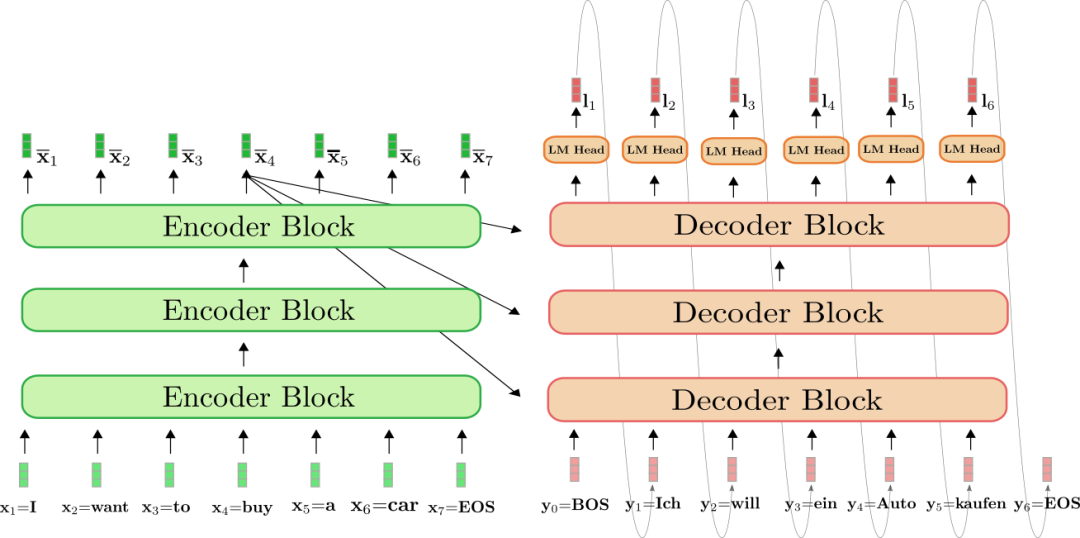
那么既然时间开销都在右边这个decoding的阶段,那就想办法解决它。那就是刚刚那篇文章介绍的KV Cache。作者提到的内存墙的问题也是这个问题的切入点,如何让计算单元更迅速的从存储单元获取数据,Paged Attention和Flash Attention都是来解决这个问题的。MQA的本质是减少了数据读取次数,第一次读取进来的K和V给所有的Q用,就放在缓存里。文章里详细讲解了MQA和GQA,这里不再赘述,但有一点值得注意的是,这两种办法再使用的时候可能并不能只是在推理的时候直接改变结构,也许要像作者说的那样:
如果要用 MQA 和 GQA,可以是从头训练的时候就加上,也可以像 GQA 论文里面一样,用已有的开源模型,挑一些头取个 mean 用来初始化 MQA 或 GQA 继续训练一段时间。
Text Generation Inference
Transformer结构优化
经典的Transformer架构出来之后,很多工作都在这个架构之上进行了魔改,希望能加快transformer的推理速度,推荐阅读survey Efficient Transformers: A Survey , 目前该review已经是第三版本,最新版本是2022年3月份出的,所以内容里没有flash Attention以及一些更新的技术,希望作者快快更新第四版本的review,技术迭代太快了,亟需大神肝的review总结。
大部分Transformer结构改进的方法的目标都是为了降低GPU的显存占用,也就是提高运算效率,将GPU的运算效率拉满,这就涉及到很底层的对于计算机系统结构的知识。
flash Attention
Flash Attention (Fast and Memory-Efficient Exact Attention)详细介绍可以阅读ELI5: FlashAttention,这是除了了multi-query attention技术之外用的比较多的加速推理的方式,当然Paged Attention算是vllm火起来之后的后起之秀。当然也可以阅读paper
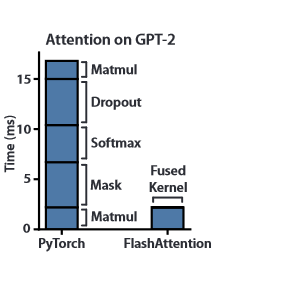
在medium的这篇博客里作者首先澄清两个概念,一个是FLOPs(每秒钟浮点运算次数)和IO,前者在GPU的更新换代的情况下获得了高速发展,而GPU的计算单元和显存间的通信却没有获得同样数量级的增长。而从上图可以看出来(原文paper中的),Attention的计算过程中大部分时间都是memory-bound导向的运算,而计算密集型的操作比如矩阵乘法其实只占了耗费时间的一小部分。
传统的attention计算步骤:

注意这里的HBM是:
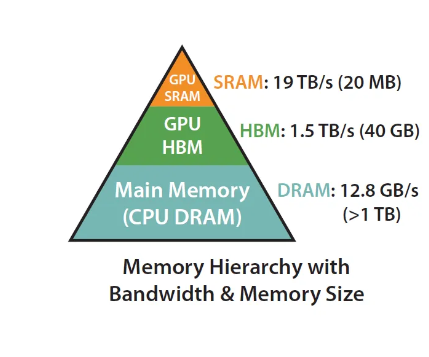
最上面一层是GPU的缓存,中间是高带宽内存,可以理解为GPU的显存,也就是你去买显卡,标注在显卡上的存储,这部分存储会大一点,运算单元需要从这里拿数据到计算单元去计算,可以直接交互,也可以先存储在缓存SRAM内,缓存会比HBM快很多。
从标准的attention计算看到有很多不需要把计算中间结果写回HBM的环节。至于FlashAttention计算推导部分我看了上面的英文博客和从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能,还是没能理解,感兴趣的小伙伴还是自己去知乎这篇文章里好好看一下。
Paged Attention
FLAT Attention
并行 Parallel Processing
推荐阅读
- Large Transformer Model Inference Optimization lilian的博客,在文首推荐的知乎文章大抵参考了这篇博客,虽然是1月份的文章,但还是推荐阅读食用