写这篇博客的初衷是自己一直以来都在关注supervised finetuning,但对强化学习这一块一直都没有过多的涉猎,一方面是因为它是大模型技术模块里相对成本比较高的过程,还有一方面是我对强化学习没有系统性的学习,觉得有一丢丢的难理解,躺在list里的斯坦福的强化学习课程也一直搁浅,传送门: cs234n, 课程视频和PPT都是可以免费下载的。
我这篇博客主要是受llama2模型的paper的启发,觉得这篇文章在RLHF方面写的非常之细致,并且代码也进行了开源,可以对照代码进行学习. 移步这篇文章的3.2节。当然也有很多博客详细介绍了这篇文章的强化学习部分的细节,参考【LLM】Meta LLaMA 2中RLHF技术细节
首先RLHF包含了两个步骤,第一个就是训练一个reward modeling来对LM生成的回答进行打分,这个分数是一个数值型的数据;第二部分就是用这个RM去调整我们的LM,使得LM能output更符合人类期望的回答。也有作者将SFT放到了RLHF的第一阶段,比如A Survey of Large Language Models 的5.2.3节将RLHF分为了三阶段:
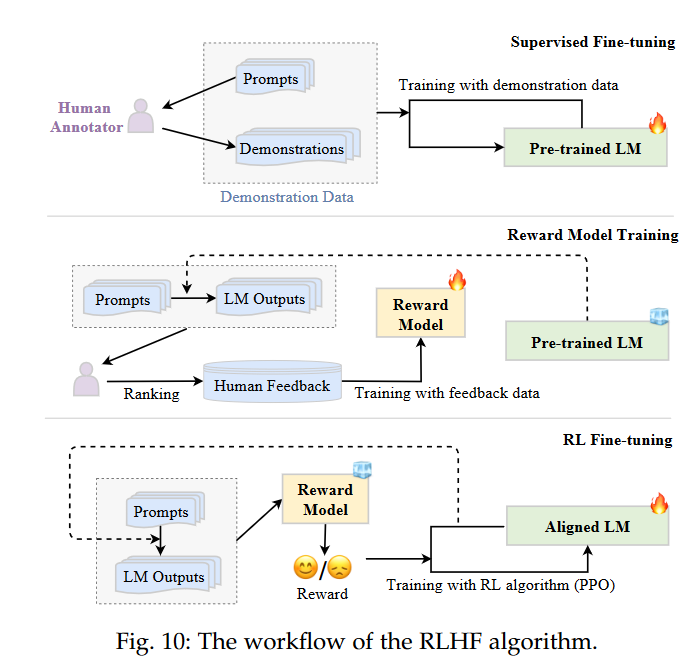
不过我认为SFT还是隔离开讲比较好。
Reward Modeling
数据
prompt好准备,那么打分这个就要靠人来打分了,人打分有一定的主观臆测性,所以就换成了比较哪一种回答比较好,像LLAMA2的做法就是分了四个等级:significantly better, better, slightly better or negligibly better / unsure。
RM模型
hugging face blog 中有一段话:
这个过程中一个有趣的产物是目前成功的 RLHF 系统使用了和生成模型具有 不同 大小的 LM (例如 OpenAI 使用了 175B 的 LM 和 6B 的 RM,Anthropic 使用的 LM 和 RM 从 10B 到 52B 大小不等,DeepMind 使用了 70B 的 Chinchilla 模型分别作为 LM 和 RM) 。一种直觉是,偏好模型和生成模型需要具有类似的能力来理解提供给它们的文本
RM的训练
直观上理解我们现在有了prompts,也有了这些prompts的generation在我们的LM上的的generation的评分ranking,那么怎么来用这些数据训练呢?
就拿LLAMA2的做法来说,它用了一个和预训练模型一模一样的模型作为RM的初始模型,唯一不同的是将LM中用作预测下一个token的分类头替换成了另一个可以输出分值的回归头就像下面这样:
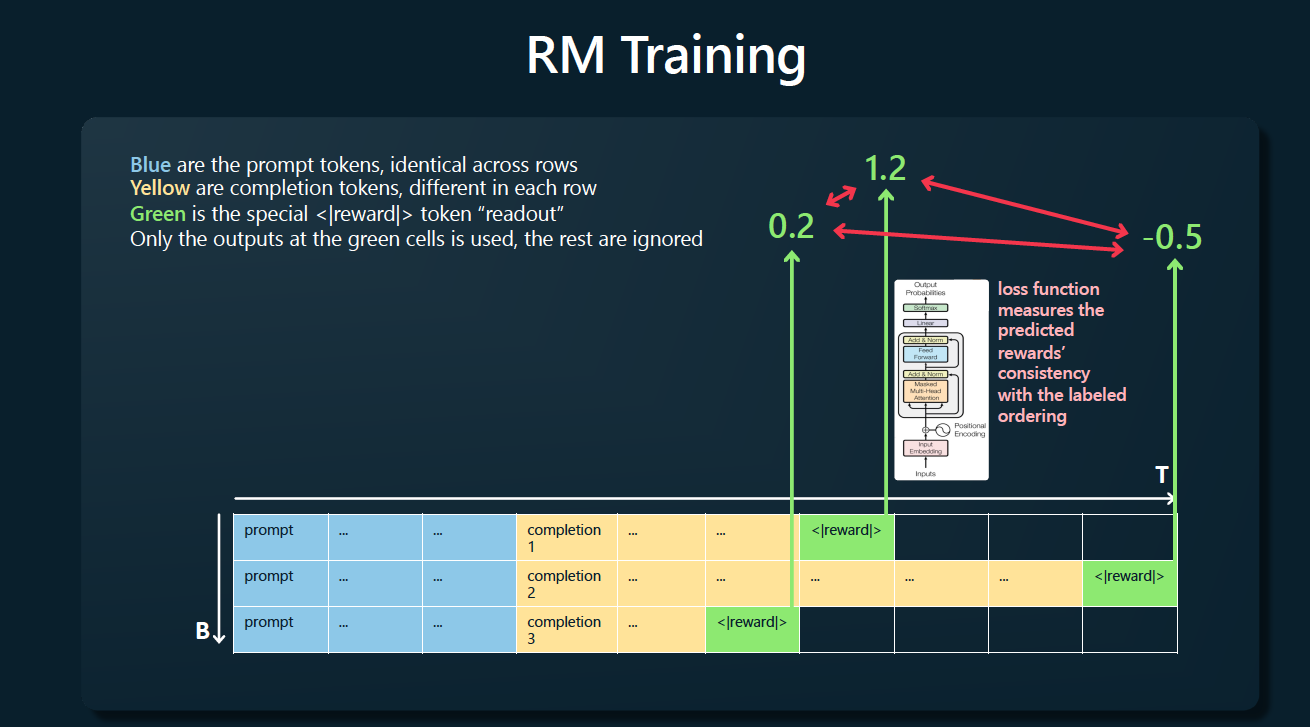
上图出自state of GPT。
loss的计算采用的是ouyang 2022的Training language models to follow instructions with human feedback 提出的计算方式:
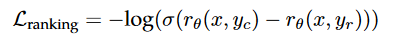
其中r是RM输出的标量值代表分值。不过llama2的做法在这个loss基础上加了一个margin,刚刚提到它在人工标注这些generation的时候分了四个档次,有的回答会比另一个对手super better,有的只是稍微好一点,所以这种“好的程度”可以在loss中区分出来,所以作者在loss的的计算里加了一个margin:
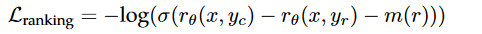
super better的就用一个比较大的m值。
RL Fine-tuning
推荐阅读
- https://github.com/opendilab/awesome-RLHF
- LLM Meta LLaMA 2中RLHF技术细节