构建和评估RAG应用
最近吴恩达出了一个小课程,传送门: Building and Evaluating Advanced RAG Applications。B站也有人搬运了,有中英文字幕。最近也正好在做RAG相关的项目,看到这个课程里有一些新的东西,权当在这篇博客里总结记录。
另外还推荐阅读一篇综述Trends in Integration of Knowledge and Large Language Models: A Survey and Taxonomy of Methods, Benchmarks, and Applications, 该综述的第三章详细介绍了retrieval augmentation的方法。我这篇博客会首先理顺一些理论,然后再介绍吴恩达课程里的知识(个人认为吴大佬出的关于LLM的一系列shot course可食用性不够高,比如上面说的这个RAG相关的课怎么看都觉得是在推广LlamaIndex这个框架,对于原理一句话带过,很多细节不清楚)。
3.2节提到的两个工作值得注意:
- Query2doc
Query2doc prompts the LLMs to generate a pseudo-document by employing a few-shot prompting paradigm. Subsequently, the original query is expanded by incorporating the pseudo-document. The retriever module uses this new query to retrieve a list of relevant documents.
- Rewrite-Retrieve-Read
Different with Query2doc,they adopt a trainable language model to perform the rewriting step
在抽取的context的使用上,我们一般的认知是加入到prompt里,告诉LLM根据这个context回答某个query,这篇综述在3.2节还概括介绍了另外两种使用knowledge的方式:
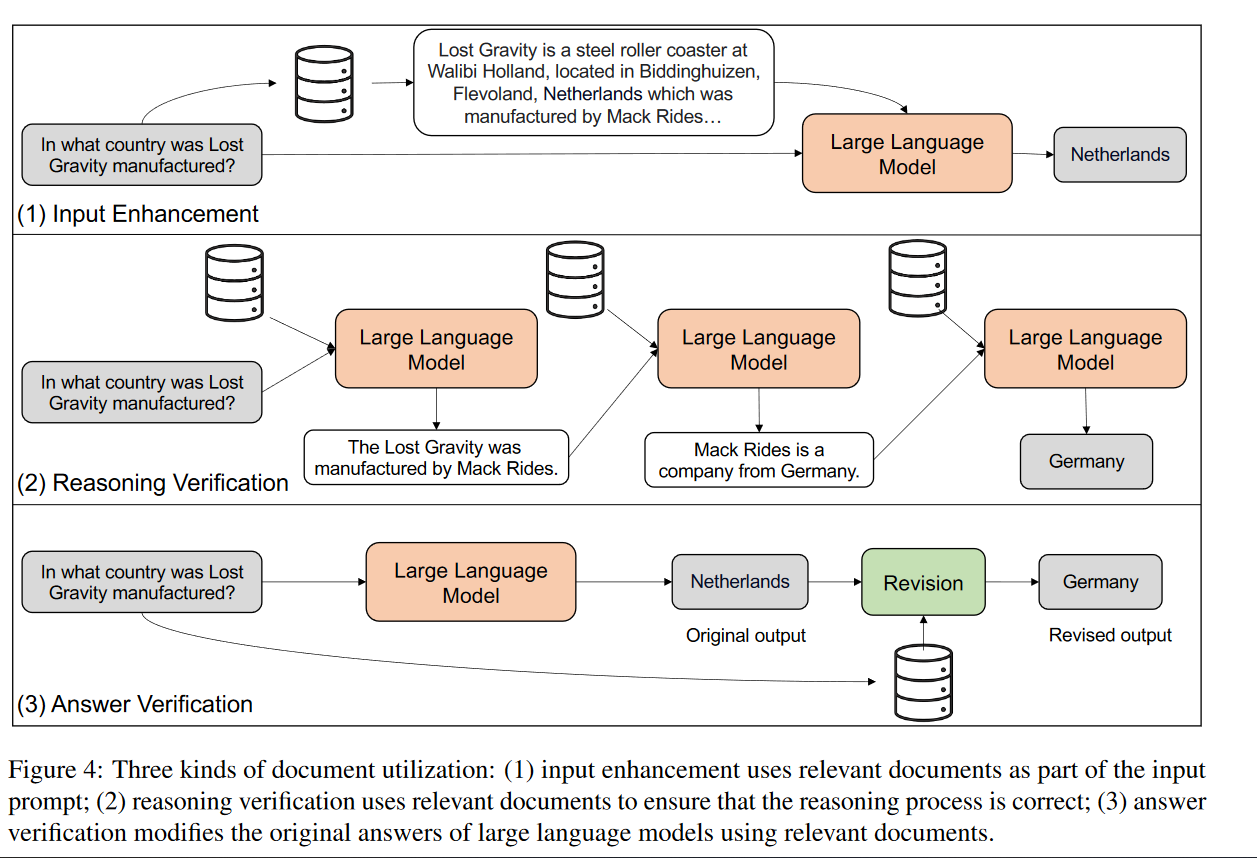
我个人认为第二种方式实操性差一点,第三种和第一种应该是大家会普遍采取的方式,第二种需要更多精细的prompt设计。
以下为课程相关的 ,传送门: Building and Evaluating Advanced RAG Applications. 课程笔记参考Frameworks in Focus: ‘Building and Evaluating Advanced RAG’ with TruLens and LlamaIndex Insights
构建 Construction
简单的RAG构建的资料太多太多了,最简易的RAG构建可以参考Simple RAG for GitHub issues using Hugging Face Zephyr and LangChain.
RAG中两个最核心的模块: Retrieval 和 Generation (Read),内部都有很多可以enhance的地方。这里列举一些可以查阅的资料,内整理了一些对于RAG的enhancement的点:
- Retrieval-Augmented Generation for AI-Generated Content: A Survey Chapter 3
- Retrieval Augmented Generation (RAG) Enhancement for LLM-based Prediction — RELP
- Advanced RAG Techniques: an Illustrated Overview 这个博客整理的挺全面的
- Advanced RAG on Hugging Face documentation using LangChain
上面这张图来自于langchain的cookbook,蓝色部分是作者认为all possibilities for system enhancement。我这里只对一些我关注的技术做整理和探索。
Chunking
有一堆文档,如何将这些文档切分成“完美的”chunk。
我比较关注的是对PDF格式的文件的处理,比较有参考价值的资料:5 Levels Of Text Splitting,内介绍的level1和level2的切分方式都是现在比较常见的。
对于PDF中的图片,也有博客进行了探索
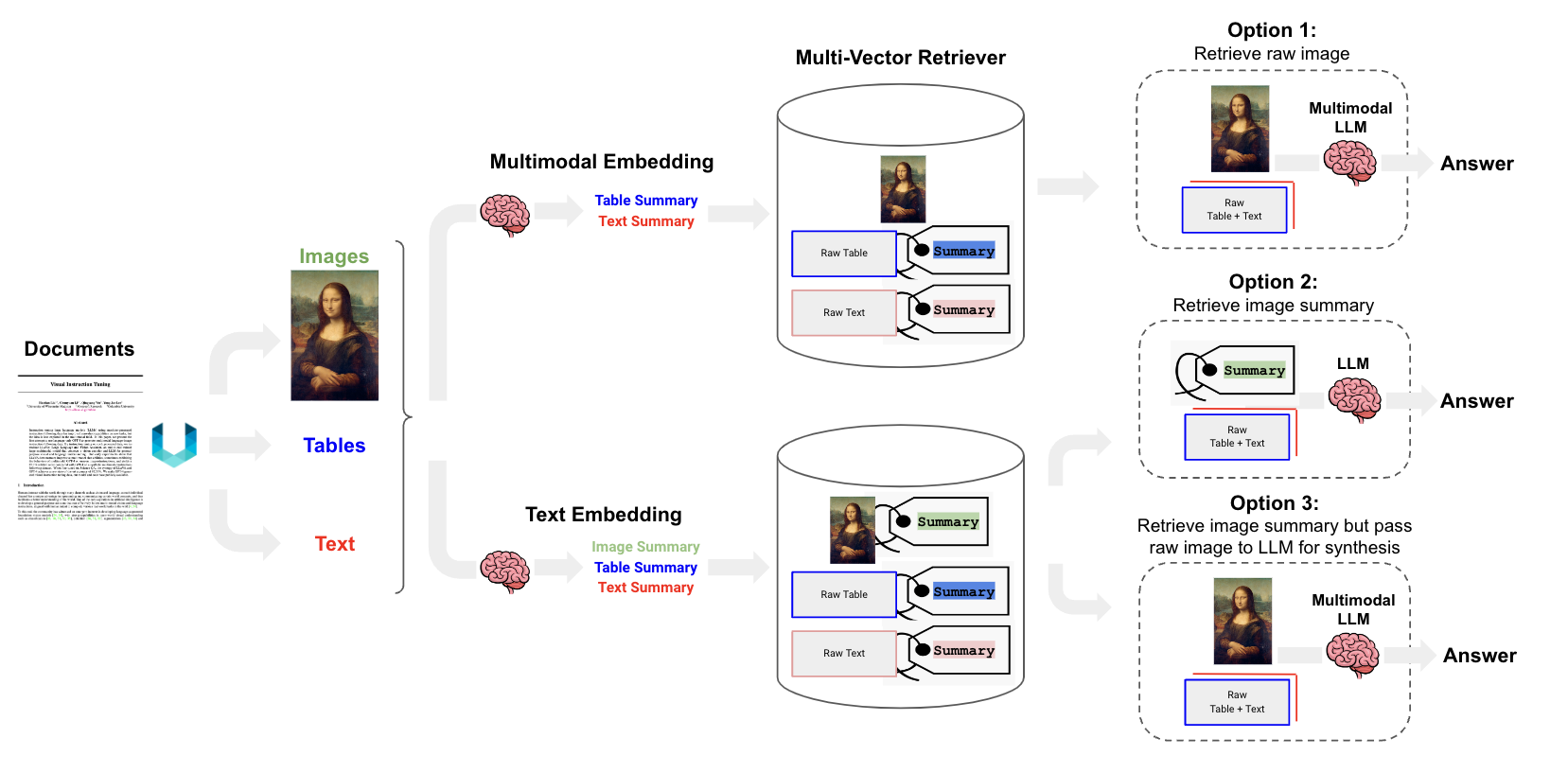
对于PDF中table的处理,一个可行的方式是用Unstuctured这个library抽取出HTML格式的table,然后用LLM将其summary一下,那么对于retriveal的时候,是将summary的vector和query的vector去进行比对的,如果match上了,就会把原生的HTML的表格表示输入给LLM去生成最终的答案。做法详见Semi-structured
RAG。-17152442960173.png)
对于PDF中图片的处理,也是对image先用LLM总结描述一下。其实5 Levels Of Text Splitting里面介绍的方法都是可以的,但我觉得实操会有一定的难度。因为PDF中的images是会被单独放到一个文件夹里的,前后夹的文本其实是丢失了,这样不可避免的就会丢失一定的语义信息。表格其实还好,但是很多时候贴了一张图片之后,后面的文字基本上是相关联的。这时候需要把图片的信息和后面的文字结合起来就需要知道每一个图片所在pdf的位置,我目前看到的资料还没有很好的解决这个问题。
评估 Evaluation
该课程建议从三个维度来评测一个RAG Application的好坏:
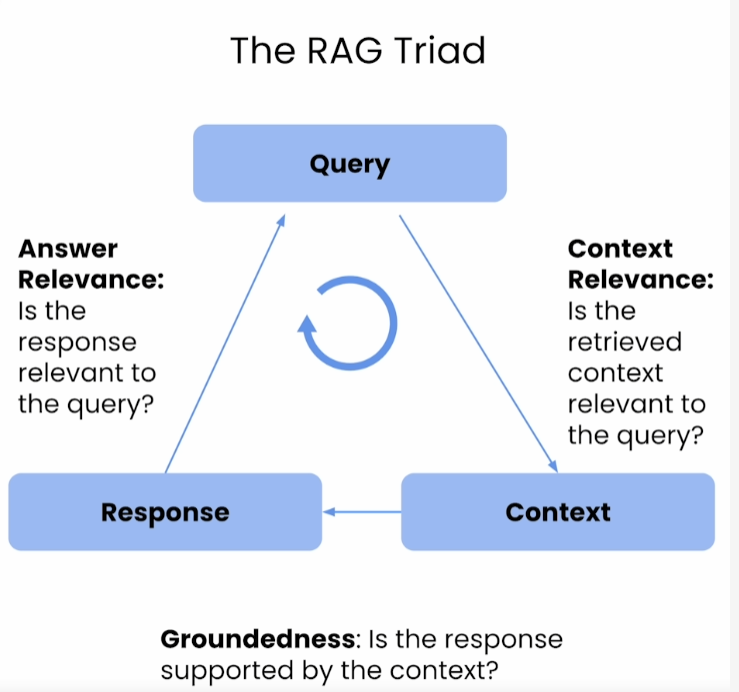
- 问题和回答的相关性
- 根据问题抽取出来的context和问题的相关性
- 回答和context的相关性
该课程主要目的是宣传自己的框架Trulens(目前该框架在github有1.8k star,热度不咋高),如果想了解Evaluation的全景知识建议看一下Retrieval-Augmented Generation for Large Language Models: A Survey
上面的review中很重要的两个总结:
- 上面所说的三个quality score如何计算?可以看到仍然是我们熟悉的一些metrics
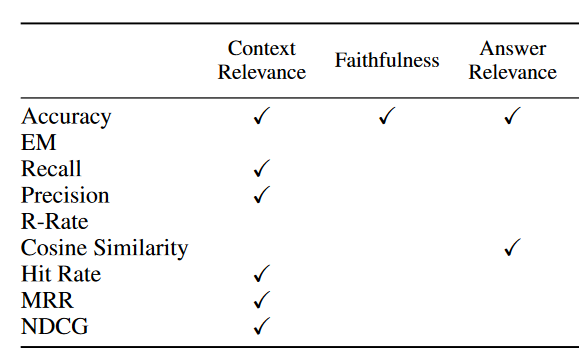
- 现有的可用评估框架有哪些?
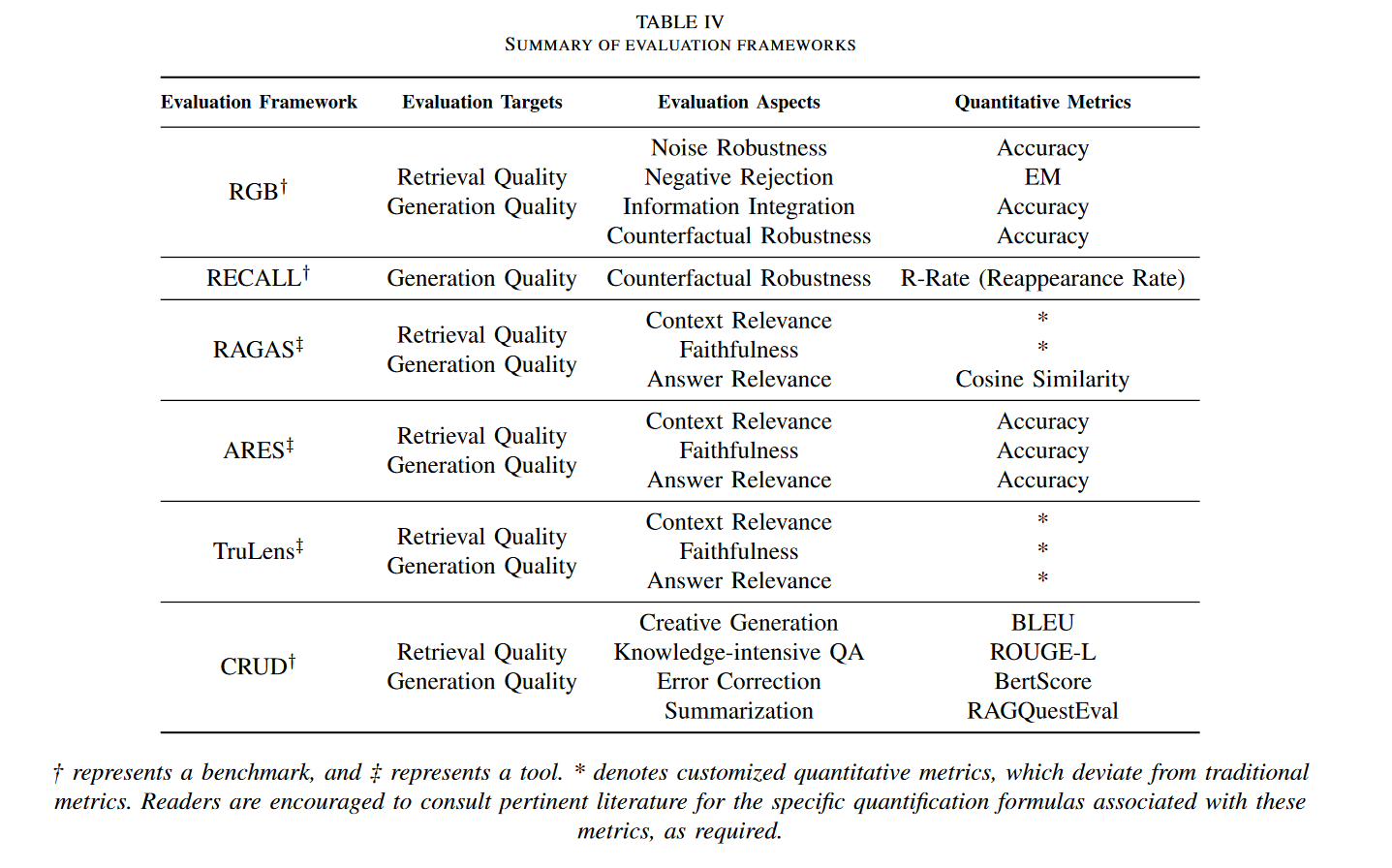
我们上面提到的课程里使用的就是该表格中列出的TruLens. 上面这张表格总结的还不是特别全面,而且没有datasets的整理,24年新出的文章CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of Large Language Models 中对这部分做了整理:
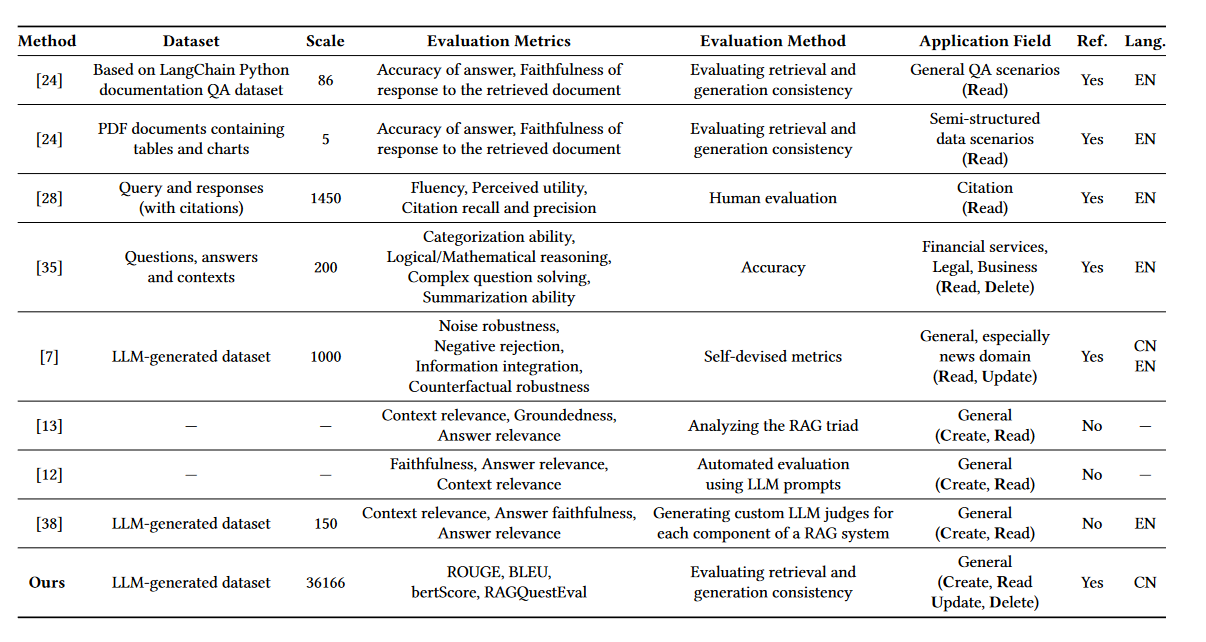
这里做一下update,在作者写这篇文章时,综述Retrieval-Augmented Generation for Large Language Models: A Survey还未对评估的数据集做整理,但最近一期3月的论文更新中已经有了这部分的内容。主要增添了对于每一个评测任务的数据集的整理。
其中[7]就是RGB,它数据的生成是利用一系列收集到的news report,然后利用LLM来基于这些report生成relevant events,questions和answers。[38]是ARES,利用flan-t5来生成的一系列合成query和answer。其中比较重要的一列是是否有金标准,也就是上图中的倒数第二列。 13,12以及38分别是TruLens-Eval,RAGAS和ARES,这三个是不需要金标准的,不过代价是需要用到Chatgpt来做自动评估呀,这些可都是白花花的银子。使用Trulens-Eval都是需要配置openai的API的。
LangChain Benchmark
对于想要快速去搭建一个评估RAG的框架的人来说,最好是有现成的可以直接用的评估体系,省去自己搜集数据以及编写各种计算metrics的麻烦。langchain提供了这么一个benchmark包,介绍传送门,截止到24年3月,该库已经包含了三个开源数据集,两个是上面介绍的python文档和pdf的QA问答数据集,还有一个是正在开发中的基于PPT的问答数据集:

这份langchain官方教程里用了好多新的tool,其中一个就是Smith, 在notebook中clone的所有数据集都可以在这个平台上看到,有点像console。LangChain Docs Q&A的数据长这样:
1 | { |
langchain-benchmark总体而言还处于初期,对于retrival的task也只有三个数据集做支撑,定制化的程度不是特别高。具体可以参考langchain-benchmark官方教程。
今天在看huggingface官网文档的时候又看到官方出了新的evaluation的guidebook,这份代码里写的相当详细,不再是一个普通的RAG评估流程,还介绍了评估数据集的生成方式,最重要的是还做了数据集的filtering,这份教程对于企业内部生成自己的评估数据集是有很大的参考价值的。
CRUD
现在我们花点篇幅来详细说一下CRUD这个中文评估benchmark。作者的出发点在于评估一个RAG的应用,要区别于评估一个LLM模型,下面这句话是作者从四个维度来评估RAG的出发点:
Lewis et al. [25] argue that the core of RAG systems is their interactive way of combining LLMs with external knowledge sources
RAG和LLM的交互方式,也就是RAG帮助LLM做了哪些东西让LLM能更好的回答问题,作者觉得是这四个方面:Create,Read,Update和Delete.

Read很常见,RAG会从知识库中搜集更多的信息来供LLM回答问题,Update主要是为了解决LLM无法回答具有时效性的问题,或者当时训练模型时没有加入的信息,Delete这点其实在我看来有点牵强。Read和Update这两点确实是评估一个RAG很关键的方面。
做RAG的评估,最重要的两点就是:
- 数据集的准备,作者打算从上面四个维度去衡量一个RAG的好坏,那就得准备相应的数据集,这部分的工作是我们平时自己做测评的重点
- 测评metrics的选择,除了我们熟知的BLEU,ROUGE,还有bert判分。其中还有作者基于QuestEval创造的RAGQuestEval评分。这个metrics还挺有意思的。这里放在这里详细介绍下:
首先基于ground truth sentence生成一系列的问题,生成问题的prompt设计是这样的:
你是一位新闻编辑,现在,你被提供了一篇新闻,请先从新闻中抽取出你认为重要的所有关键信息(通常为一个关键词,包含文章中的所有实体和名词性短语),然后,根据关键信息设计几个问题,考验大家能否正确回答问题。用json的形式返回答案。以下是个例子。
新闻:2014年,全国新增并网光伏发电容量1060万千瓦,约占全球新增容量的四分之一。其中,全国新增光伏电站855万千瓦,分布式205万千瓦。据统计,2014年中国光伏发电量达到了250亿千瓦时,同比增⻓超过 200%。
{json_response}
现在你需要为这篇新闻设计问题,尽量涵盖大多数关键信息,请尽量让答案可以用两三个词回答,答案不能太长,key_info包含文章中的所有实体和名词性短语,question与key_info一一对应,数量一致,输出用json的格式:
{news}
注意这里先让LLM抽取文章中的所有实体和名词性短语作为关键信息,question是根据这些关键信息生成的。问题生成完之后分别用reference sentence和ground truth sentence作为context,去让LLM回答上面生成的问题。如果遇到无法回答的问题就让LLM答“无法回答”. 最后一步针对回答的结果计算precision 和 recall。
该文章作者在数据的处理方面,选择去爬取网上最新的news,然后用这8000个新闻建立了三个task的数据集:open-domain multi-document summarization(考察RAG的delete能力),text-continuation(考察RAG的Generation能力),question-answering(read能力)和hallucination modification(考察RAG的Update能力)。
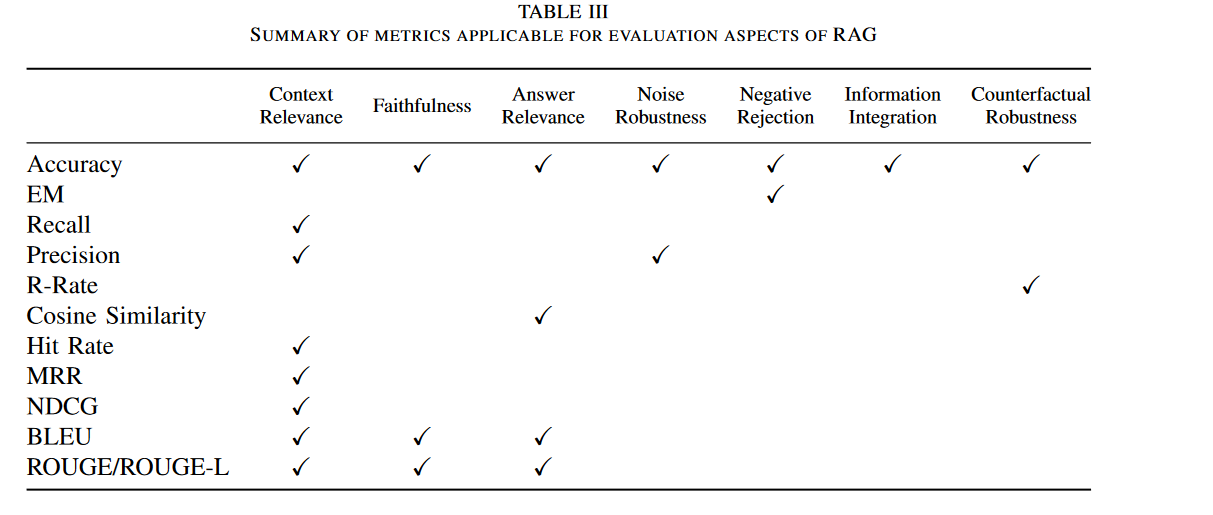
其实仔细看上面review中的总结,CRUD这篇文章里提到的应该考察RAG的“哪些能力”还是不够全面的,而且我个人认为CRUD里面仅仅是以end-to-end的方式计算generated anwser和gound truth之间的差距也是不太可取的,它没有涉及到RAG里面很重要的一个环节:retrieval。更全面的方式应该是计算三种quality scores(具体参考review的介绍):
- context relevance: query 和 context 的关系
- faithfulness(groundness):answer 和 context 的关系
This measures the factual consistency of the generated answer againest the given context
主要用于检测LLM的幻觉。这里博客 对trulens的计算方式做了详细介绍,注意它里面的prompt的设计。Ragas框架对于faithfulness的计算查看Faithfulness,也是用chatgpt来把answer中的statement拆开然后分别去与召回的context做对照,可以查看ragas框架计算faithfulness的代码.
My spicy comment: trulens和ragas两者还挺类似的,就是ragas除了计算faithfulness,还多了好几个metrics,如context precision, context recall, context entity recall。其实就是把context relevance这个metric拆分地更细了。不仅如此,ragas把answer relevance也拆的更细了,它包含了answer correctness, answer relevance和answer similarity. 相比较而言,ragas在笔者写这篇文章的时候,star数是要比trulens多的,前者4.8k,后者1.8k。而且issues明显要多于trulens,直觉上看应该是ragas用的人比较多。
在整理这部分metrics的时候,也搜了一下大家都在用什么样的框架来评估自己的RAG,看到reddit上也有人有这样的疑问Why is everyone using RAGAS for RAG evaluation? For me it looks very unreliable, 我觉得其中一个回答比较贴合当下对于RAG评估的一个现状:
There is no proper techincal report, paper, or any experiment that ragas metric is useful and effective to evaluate LLM performance. That's why I do not choose ragas at my AutoRAG tool. I use metrics like G-eval or sem score that has proper experiment and result that shows such metrics are effective. I think evaluating LLM generation performance is not easy problem and do not have silver bullet. All we can do is doing lots of experiment and mixing various metrics for reliable result. In this term, ragas can be a opiton... (If i am missing ragas experiment or benchmark result, let me know)
https://www.reddit.com/r/LangChain/comments/1bijg75/comment/kvoj1q8/?utm_source=share&utm_medium=web3x&utm_name=web3xcss&utm_term=1&utm_content=share_button
- answer relevance: answer 和 query 的关系
至于计算出上面这三个方面的数值,有多种方式。有用LLM的,比如Trulens就是用的chatgpt,也可以用claude,参考见基于大语言模型知识问答应用落地实践 – 使用 TruLens 做自动化 RAG 项目评估测试。也有直接计算相似度的,比如我们熟悉的bert score,rouge-L。review在这里也进行了整理:
Customization模式
其实在具体的业务场景下,如果已经搭建了一套RAG系统,如何来评估这个RAG系统的好坏,更合理的方式还是需要用自己的数据来测评,如果只是用一些公开的benchmark,如上面提到的langchain benchmark,还是CRUD提出的以新闻为数据的benchmark,都有一点不那么让人信服,毕竟你费劲巴拉地搭建一个RAG的chatbot,还是要在自己的具体的业务场景表现好,客户才会买账吧。
但更多情况下,业务场景下往往是缺少金标数据集的,这时候就需要去针对自己的业务场景去生成一些“合成”数据集。我们可能基于的就是一堆的业务文档,这些文档有的是PDF,有的可能是word,也会有PPT,如果根据这些文档去生成自己的评测数据集,这样基于这个评测数据集我们再去“调整”我们RAG中的各个能影响RAG performance的环节:embedding模型选择哪个,LLM选择哪个?chunking应该如何优化等等?加了rewrite和rerank等techniques之后有没有让RAG的效果变好,这里的变好仅仅是指在我们自己的业务数据上变好,而不是在其他开源的benchmark上,这样才具有一定的说服力。
参考博客RAG Evaluation, 文章介绍了一种根据documents生成synthetic evaluation dataset的办法,里面还加了一些tricks:如何用一个critique agents去筛选QA。不过该篇文章evaluation环节仅仅计算了answer和query的关系(faithfulness),它给出的理由是:
Out of the different RAG evaluation metrics, we choose to focus only on faithfulness since it the best end-to-end metric of our system’s performance.
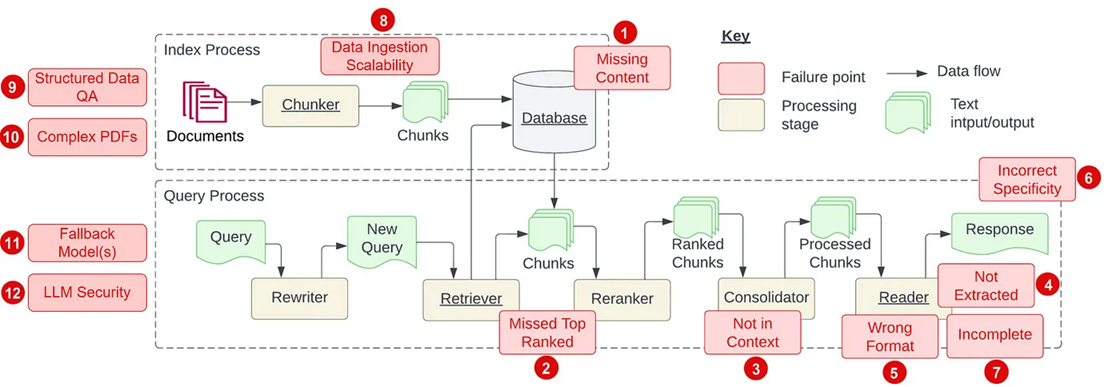
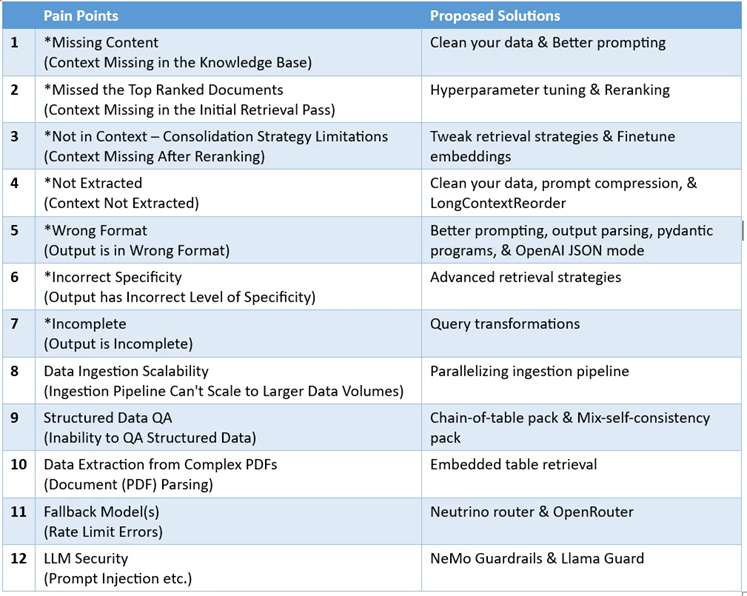
RAG 中的PainPoints
参考:
上面视频对应的博客