生成模型
在这个全民皆Difussion Model的时代,已经有人忘却了曾经的王者GAN。这篇博客是自己记录学习生成模型,这里的生成模型仅局限于生成图片的模型,不是LLM这一类自然语言生成模型。启发点有两个: - 在斯坦福cs231n这节课里,GAN这一章节详细讲解了从VAE到GAN的发展脉络,并没有延申到Difussion Model。Difussion Model的内容放到cs236中去讲了。 - Lilian Blog曾写过一篇What are Diffusion Models?, 内扩展了两篇介绍: GAN 和 VAE。
Self-supervised Learning
自监督学习中最出彩的就是对比学习。
Contrastive Learning
参考:
- Contrastive Representation Learning
- Contrastive Representation Learning — A Comprehensive Guide (part 1, foundations)
The goal of contrastive representation learning is to learn such an embedding space in which similar sample pairs stay close to each other while dissimilar ones are far apart.
对比学习的本质思想是:将positive的sample和negtive的sample距离分割的越远。cs231n中的lecture12发展逻辑捋的很好,是因为需要一个更general的pretext task:
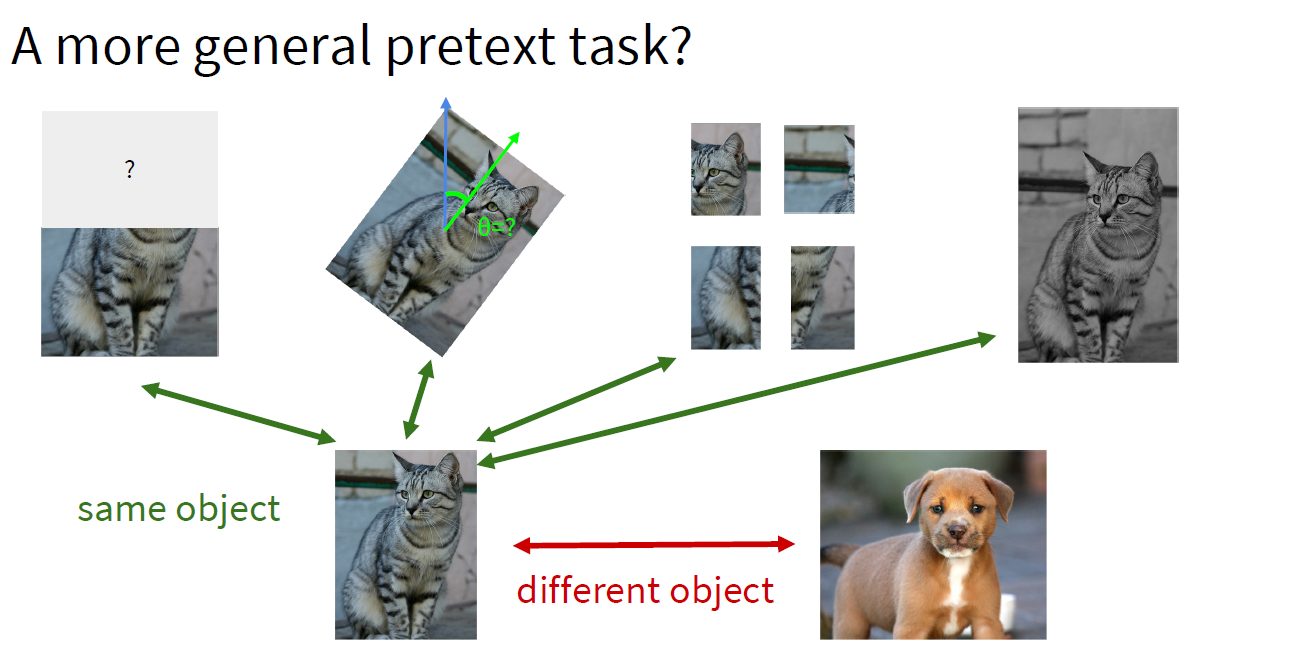 之前的pretext task都是基于"visual common
sense",例如预测rotations,画面修复inpainting, 颜色填充colorization等,
造成的问题是"learned representations may not be general"。
之前的pretext task都是基于"visual common
sense",例如预测rotations,画面修复inpainting, 颜色填充colorization等,
造成的问题是"learned representations may not be general"。
在contrastive
learning中有一个loss比较重要:infoNCE,是在Representation Learning with
Contrastive Predictive
Coding文章中提到的,这个loss就是为了上面的本质思想量身定制,如何将一个class的sample拉的更近,而不属于一个class的sample拉的更远呢?

这里我贴一下chatgpt对于上述公式为什么可以作为损失函数的解释,比我自己组织的语言要好:

那么我们有了基本思想和loss函数之后如何训练这个网络呢?A Simple Framework for
Contrastive Learning of Visual Representations
这篇文章给我们介绍了一个SimCLR,可以重点阅读一下。文章内给出了算法伪代码:

SimCLR也披露了自己的训练代码:https://github.com/google-research/simclr?tab=readme-ov-file
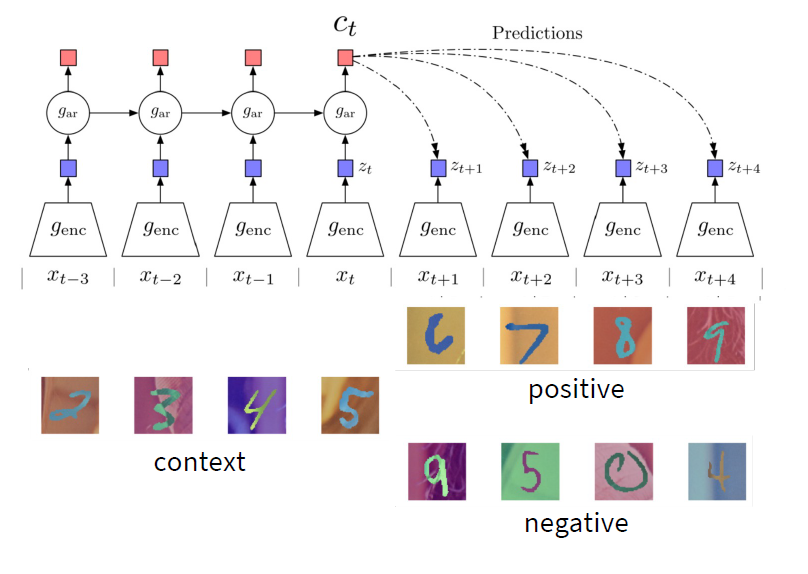
SimCLR属于Instance contrastive learning中的一种,包括he Kaiming团队所出的MOCO以及MOCO V2,与之相对应的是另外一种contrastive learning: Sequence contrastive learning, 代表为CPC(Representation Learning with Contrastive Predictive Coding)。其实很好理解,如果接触过image segmentation这个任务的话,会记得在图像分割这个任务里有两种segmentation,一种是instance segmentation,一种是semantic segmentation。contrastive learning中的instance对比学习就是如上面图示,猫的图片它是一个class,我们将猫的图片和狗的图片的距离变大,而让猫和猫的图片的”距离“变小。对于sequence对比学习,顾名思义就是加入了序列的影响:
Generative Modeling
generative
modeling被认为是自监督学习的一种,但他们俩的目的不一样,前者是希望建立一个模型,我们用这个模型可以生成一些diverse和realistic的图片,后者是希望通过自监督的representation
learning去生成图片更好的features,用这些features去帮助下游任务拥有更好的performance。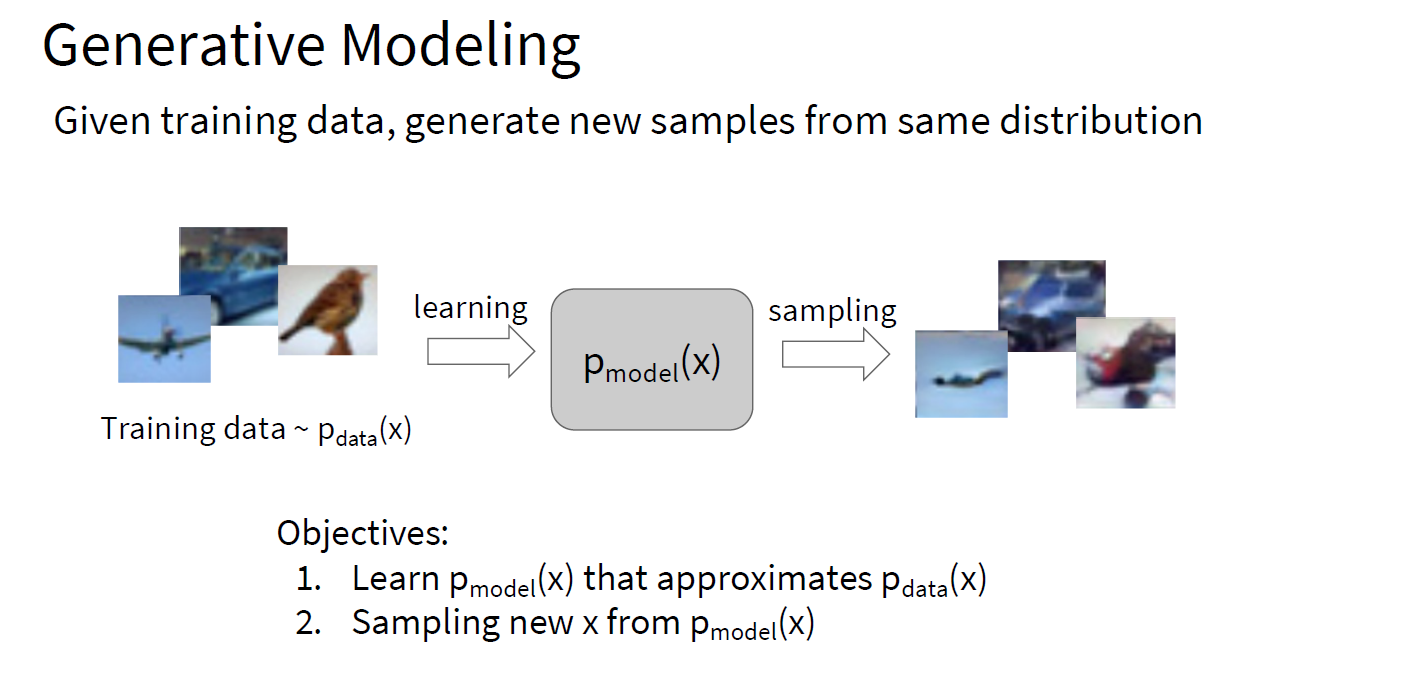
强烈建议阅读NIPS 2016 Tutorial: Generative Adversarial Networks, 作者将拟合Pmodel的方式分成两种:
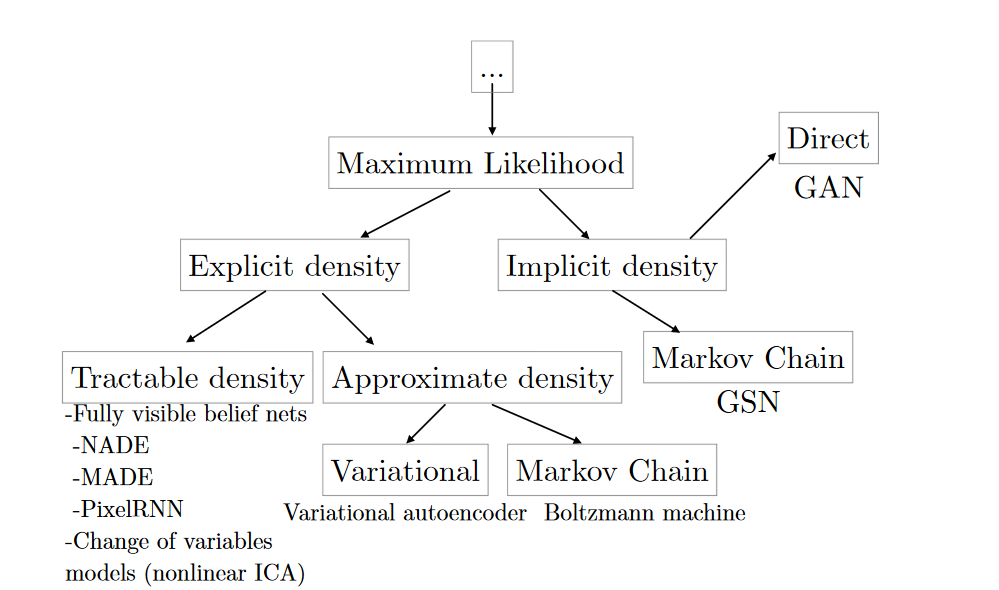
其中Explicit Density中可以Tractable
density的PixelRNN是我们所熟知的,我对于Tractable
Density的理解就是可以求导并利用梯度下降去一点点降低loss的函数,那么对于FVBN来说,拟合Pmodel的方式就是:一张图片的概率等于所有这张图片上pixel的联合概率
而近似估算中的VAE则采用的是一种引入潜在变量z的方式来间接的建模数据,导致密度函数不可解,必须采用变分推断等近似方法。那么为什么要引入潜在变量z呢?
