RAG Enhancement(提高基于RAG的问答系统中回答质量的方法论述)
去年一整年都在做一套基于RAG的问答系统,项目处理的文档主要为PDF以及中英文混杂,为了提高问答的准确性,期间我也在很多点上进行了思考,很多想法来源于这篇review paper中对于RAG enhancement方法的整理,在去年一年,我写了关于PDF的process和chunk的文章,实际应用时,我们发现文档如何切分地更好确实非常影响后续RAG回答的准确性和用户对于问答的满意度。期间也写了一篇关于RAG performance evaluation的总结,这在产业落地的过程中尤其关键,如果提供一个让顾客满意,同时兼顾算法侧科学性和数学性的要求,也是一个值得深究的topic。今天单开一篇文章,主要聚焦于:当你已经基于市面上已有架构,诸如langchain,llamaindex等高代码架构还是诸如coze,百炼,Dify等低代码架构 搭建了一个知识库问答系统,还可以从哪一些方面提高问答的准确性。
先说一个RAG的种类,我们目前接触的比较多的是典型架构:
- Query-based RAG
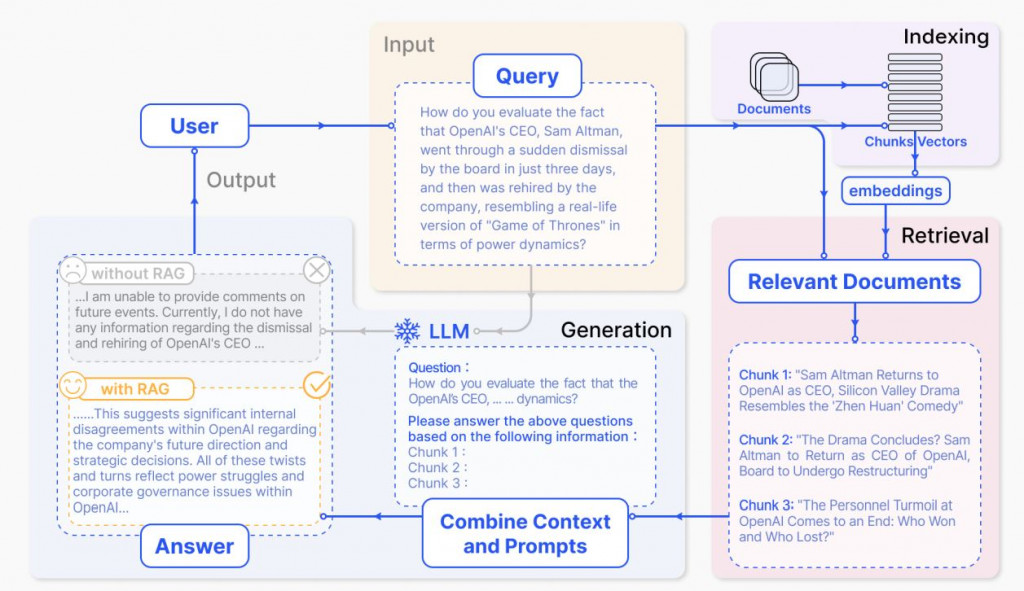
上面的这种RAG其实是query-based RAG, 主要做法就是将用户的query和从知识库中抓取的context一同包裹在prompt,塞给大模型去回答用户的问题。这个架构中如何设计高质量的prompt,对产生回答的质量影响很大。
- Latent Representation-based RAG
retrieved objects are incorporated into generative models as latent representations
这种方法需要对generator的完全掌控,如果遇到LLM只是调用API的情况,这种方法是用不了。
- Logit-based RAG
In logit-based RAG, generative models integrate retrieval information through logits dring decoding process. Typically, the logits are combined through simple summation or models to compute the probabilities for step-wise generation.
- speculative RAG
这种RAG更多的是用在处理时序数据上, It decouples the generator and the retriever, enabling the direct use of pre-trained models as components.
下面这张图是RAG种类的区别: 
RAG Enhancements
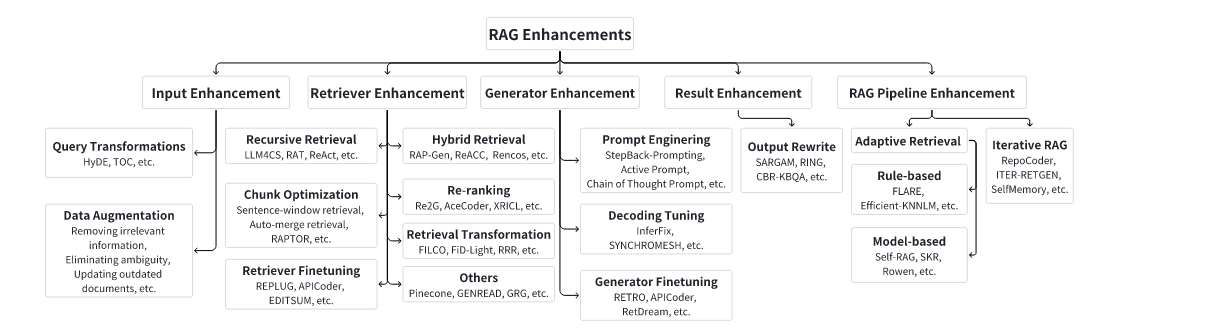
Input Enhancement
这里的input是指用户的query,也就是我们输入到retriever中的input。可以理解为query或者question。一开始我们搭建RAG的时候,这个用户的query会直接进到embedding模型中去encode出一个vector,然后用这个vector去向量数据中寻找相应的context,这会带来什么问题呢?我们在实际落地中发现:
- 用户的问题千差万别,如果没有上下文,没有背景知识,真的很难理解用户真的想问什么,这就导致到知识库中抽取的context不够准确
- 用户的query一般都比较短,同一个embedding 模型,我们既拿它encode了query,又拿它encode了context,context一般都是比较长的,这种长文本和短文本的embeddings在计算向量相似度的时候往往会不准确
- 我们现在使用的开源embedding模型诸如bge,m3e,虽然都宣称自己支持多语言(中英文)。但实际使用时发现,如果用户询问时采取的是中文,但是文档主要都是英文的,或者中文的问题想匹配英文的文档,有一定难度,很不准确,这就导致一开始抽取的context就不准,那么进到generator,LLM也不知道要怎么回答这个问题。
我们在解决中文问题对应英文文档,采取的是将用户query改写的方式,对应的是上面的query transformations。不仅是中英对应问题,我们还发现有一些完全是一样的word,也就是query完全包含了context中应该有的word,但相应的context也没有被抽取到,所以我们也采用了不同的编码方式,也就是bm25和dense encoder两者结果混合(这种方式好像并不在这个大类input enhancement下)
- query transformation
最基础的是我上面说的,query进来后调用LLM改写一遍,prompt设计为请用英文改写,然后将这些query分别去知识库抽context,另外这部分还有的方法是:
use the original query to generate a pseudo document, which is later used as the query for retrieval
我觉得一定程度上可以解决短query对应长document匹配不准确的问题。
另外还可以将query改写成很多sub queries,这就需要更精细化的设计了,有一些工作已经在这部分发了论文,移步总结
- Data Augmentation
remove irrelevant information, eliminating ambuguity, updating outdated documents, synthesize new data, etc.
Retriever Enhancement
这一部分是重点,抽取的context的准确性直接影响最终answer的质量。如果context不包含这个信息,那LLM大概率是回答不上来一些领域专业问题,尤其是一些是内部的文档。如果context包含这些信息,但是抽取的时候它的similarity score并不高,所以不排在retrieved contexts list的前列,一样可能被rerank模型筛选掉。
- recursive retrieval
循环抽,顾名思义就是query进来后分阶段去知识库中搜context,这时候就需要将query拆分为一些子问题,或者就像上面input enhancement中介绍的一样,对query进行了改写或者扩充,然后分别对这个query的list进行循环抽
- chunk optimization
最典型的,sentence-window retrieval,概念很简单,llamaindex实现了。还有将documents组织成树状结构的,hit到某个叶子节点,就把parent节点都拎起来,其实有点加重LLM输出answer的负担,后续LLM响应时间随之延长,所以这是个trade-off。这部分我们遇到的场景是PDF的解析,想过把PDF中 title作为parent节点,相应的section下的内容作为叶子节点,这种存储方式在很多向量数据,比如milvus都已经支持了。但我个人认为这种方式太精细化了,不能适配到通用场景
- Hybrid Retrieval
这种方式将dense retriever和sparse retriever结合,从而提高retrieve的准确性。这种方式可以有效解决我刚刚上面说到的,明明context中包含了query中的关键word,但没有办法被dense retriever抽出来,这时候需要加入sparse retriever,比如用BM25的encoder来编码query和context。
- Re-ranking
rerank就是对retriever抽取回来的context list进行similarity的重新排序,这一步也是提高answer质量的关键,现在也有不少开源reranker模型了。
- retrieval Transformation
retrieval transformation involves rephrasing retrieved content to better activate the generator's potiential, resulting in improved output
Generator Enhancement
这一步在落地的时候往往改进的空间不大,因为很多公司在这一步只是调用一些公有的LLM的API,唯一能做改变的地方就是Prompt的设计。
- Prompt Engineering
这一部分有工作LLMLingua将query用一个small model进行了压缩,可以加速模型的推理,一定程度上可以减轻"lost in middle"的问题,这个工作还挺有意思的。
Decoding Tuning
Generator Finetuning
Result Enhancement
- output rewrite
顾名思义,这是对generator输出的内容进行重新编排。这一步实际应用不多。
RAG Pipeline Rnhancement
- Adaptive retrieval
主旨思想就是在query进来后,在该抽context的时候抽,不该抽的时候不抽。over-retrieval会导致资源的浪费和潜在的信息冗余。