安装
参照
https://github.com/PaddlePaddle/PaddleVideo/blob/develop/docs/zh-CN/install.md
注意这里创建虚拟环境的时候要使用python=3.7,因为3.7之后的版本,paddleVideo只支持Linux系统。
其他要求: cuda >= 10.1,
cuDNN >= 7.6.4
安装完paddlepaddle之后,再安装paddleVideo
快速开始
这里官方教程写的不是很详细,安装完之后让直接用命令行方式启动程序,因为paddleVideo这个库里面有三个inference模型,分别是
1
2
3
| Inference models that Paddle provides are listed as follows:
{'TSN', 'ppTSM', 'TSM'}
|
这里安装好环境之后,直接命令行是会报错的,因为还没有下载模型参数以及label,会报'If you want to use your own model, Please input model_file as model path!'的错误。
这时候进入python环境,跑以下程序:
1
2
3
4
5
| from ppvideo import PaddleVideo
clas = PaddleVideo(model_name='ppTSM',use_gpu=False,use_tensorrt=False)
video_file='data/example.avi'
result=clas.predict(video_file)
print(result)
|
当你enter第二句话的时候,程序就会开始下载InferenceModel,大概有90.6兆,下载完之后再执行下面几行的程序,其中video_file这里要注意一下,程序里是相对路径。
下载的模型会放在
C:\Users\XXXX\.paddlevideo_inference\inference_model\ppTSM
下载的label的txt在'D:\\XXXXX\\anaconda_envs\\paddleVideo\\lib\\site-packages\\ppvideo\\tools\\../data/k400/Kinetics-400_label_list.txt'也就是虚拟环境那个ppvideo里
训练attention-lstm模型
前两节安装完之后,快速开始是为了测试安装正确与否。paddleVideo只有attention-lstm模型,并没有提供在youtube-8m上训练后的参数和label。所以这部分我们使用paddle框架来自己训练。
下载youtube-8m数据集并转换为paddlepaddle处理的格式
整个数据集包含3844个训练数据文件和3844个验证数据文件(TFRecord格式)
在linux系统下用curl下载,在windows下可以利用git的bash命令行的方式下载:
1
2
3
4
5
| curl data.yt8m.org/download.py | partition=2/frame/train mirror=asia python
curl data.yt8m.org/download.py | partition=2/frame/validate mirror=asia python
curl data.yt8m.org/download.py | partition=2/frame/test mirror=asia python
|
数据下载完成之后,因为paddlepaddle需要使用pickle的数据格式,所以需要用https://github.com/PaddlePaddle/PaddleVideo/该官方仓库里data/yt8m下的脚本tf2pkl.py脚本进行转换。tf2pkl.py文件运行时需要两个参数,分别是数据源tf文件存放路径和转化后的pkl文件存放路径。
由于TFRecord文件的读取需要用到Tensorflow,用户要先安装Tensorflow,或者在安装有Tensorflow的环境中转化完数据,再拷贝到data/dataset/youtube8m/pkl目录下。为了避免和PaddlePaddle环境冲突,建议先在其他地方转化完成再将数据拷贝过来。
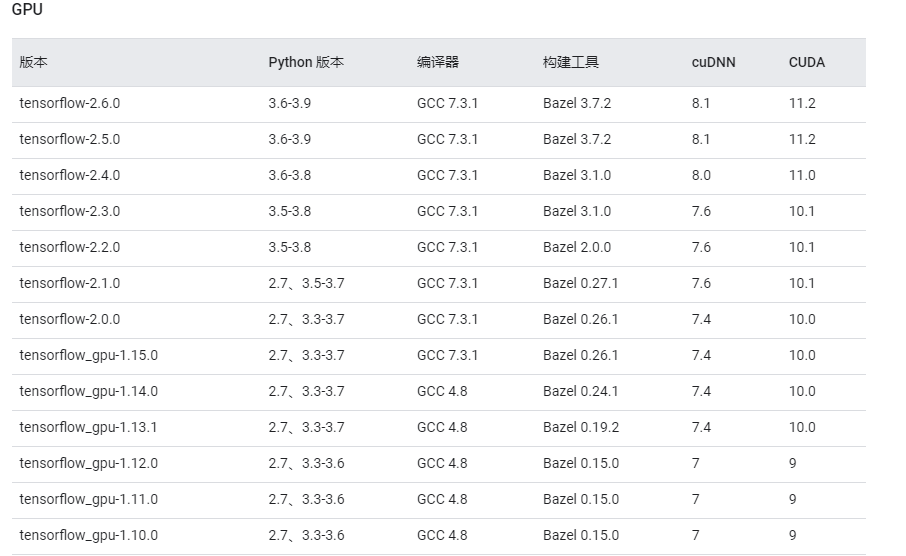
上面在转换数据格式的时候还要注意,tf2pkl.py文件用的tensorflow是1.X的版本,用2.0之后版本的需要重新创建虚拟环境,如果不想麻烦,可以直接在这个paddleVideo的虚拟环境里面安装tensorflow-gpu==1.14.0
这里如果安装的是gpu版本,需要有对应的cuda版本支持,1.14.0需要10.0的cuda,我的服务器是11.2的cuda,所以这里我就直接安装的是cpu版本的tensorflow。其他的版本支持请查阅:https://www.tensorflow.org/install/source#gpu
1
2
| python tf2pkl.py ./tf/train ./pkl/train
python tf2pkl.py ./tf/val ./pkl/val
|
我看到tf2pkl.py脚本里是用sys命令行的方式调用的,然后他整个脚本都是在linux的模式下的模式。其中有几个地方改动一下就可以适用于windows:
- 删掉以下几行:
1
2
3
| # assert (len(sys.argv) == 3)
# source_dir = sys.argv[1]
# target_dir = sys.argv[2]
|
禁用命令行调用的模式
- 将record_dir
变成你想转化的文件的文件夹的路径,比如
\data\dataset\youtube8m\tf
- 将main函数中将outputdir路径改成你要存储pickle文件的文件夹的路径。
完成上述步骤之后,直接在IDE中运行tf2pkl.py就可以开始转化文件了。
1
| export CUDA_VISIBLE_DEVICES=1
|