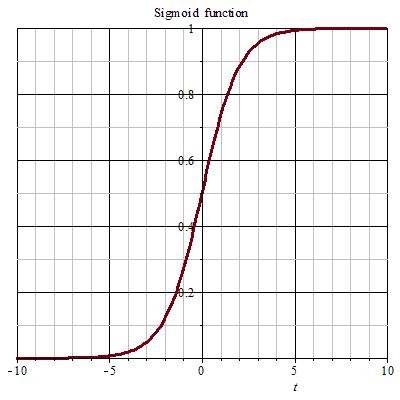
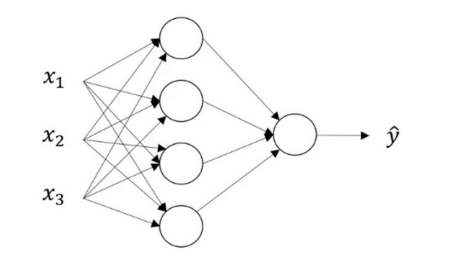
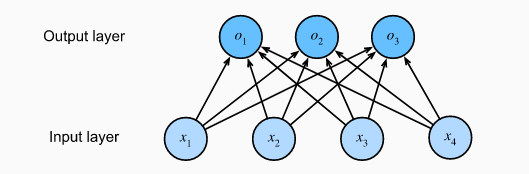
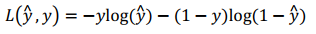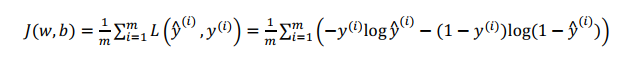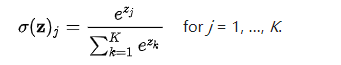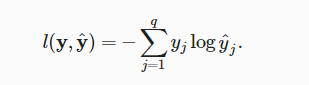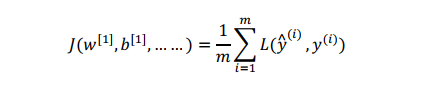defcompute_cost(Z3, Y): """ Arguments: Z3 -- output of forward propagation (output of the last LINEAR unit), of shape (6, number of examples) Y -- "true" labels vector placeholder, same shape as Z3 Returns: cost - Tensor of the cost function """ # to fit the tensorflow requirement for tf.nn.softmax_cross_entropy_with_logits(...,...) logits = tf.transpose(Z3) labels = tf.transpose(Y) cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = logits, labels = labels)) return cost
optimizer = tf.train.GradientDescentOptimizer(learning_rate = learning_rate).minimize(cost) init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) # Do the training loop for epoch inrange(num_epochs):
epoch_cost = 0.# Defines a cost related to an epoch num_minibatches = int(m / minibatch_size) # number of minibatches of size minibatch_size in the train set seed = seed + 1 minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)
for minibatch in minibatches:
# Select a minibatch (minibatch_X, minibatch_Y) = minibatch
# IMPORTANT: The line that runs the graph on a minibatch. # Run the session to execute the "optimizer" and the "cost", the feedict should contain a minibatch for (X,Y). _ , minibatch_cost = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y})
epoch_cost += minibatch_cost / num_minibatches
# Print the cost every epoch if print_cost == Trueand epoch % 100 == 0: print ("Cost after epoch %i: %f" % (epoch, epoch_cost)) if print_cost == Trueand epoch % 5 == 0: costs.append(epoch_cost)