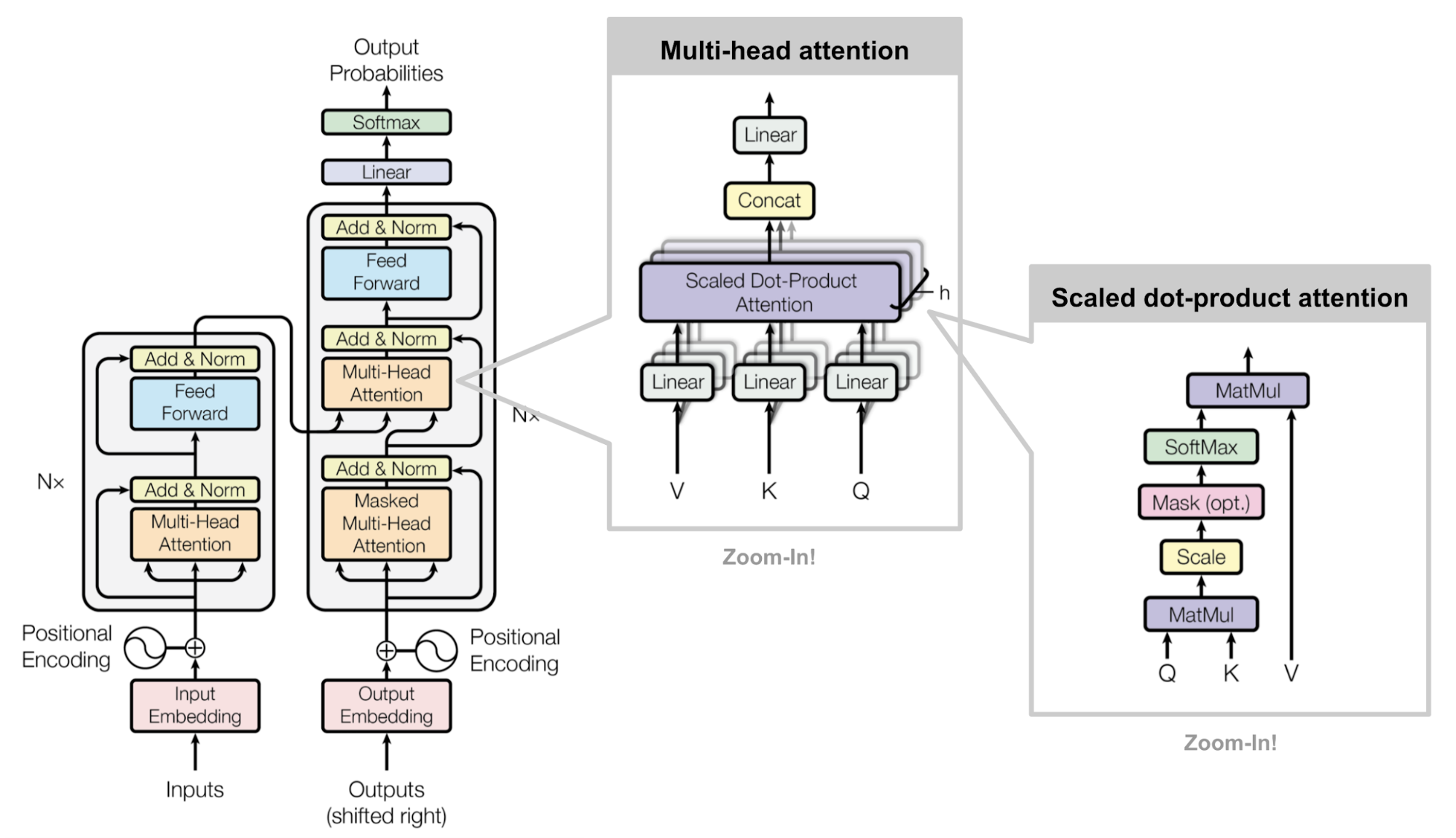
out = inp # now, (batch, seq_len, embed_size) with tf.variable_scope(scope): for i inrange(self.num_enc_layers): out = self.encoder_layer(out, input_mask, f'enc_{i}') return out
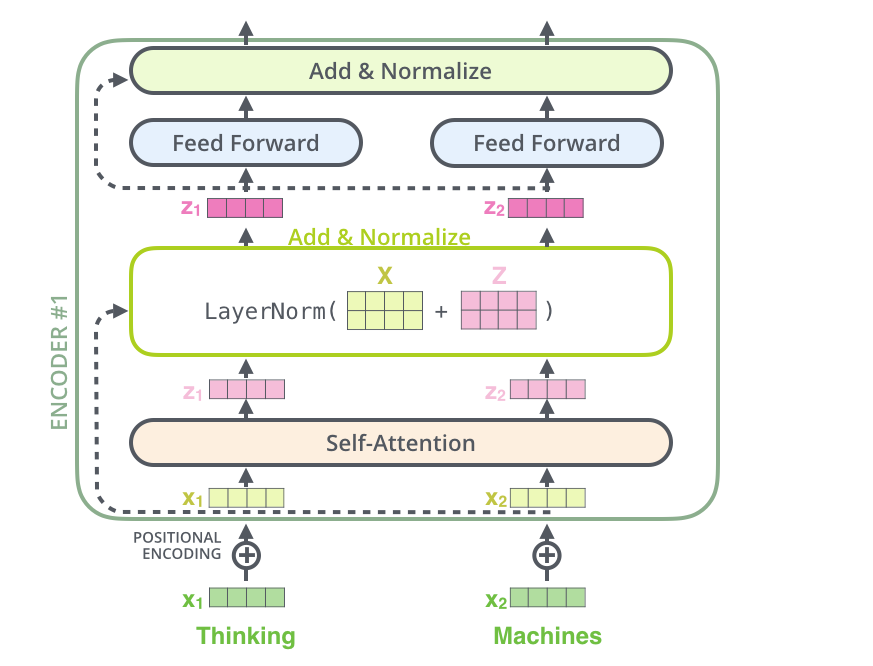
classTransformerEncoderLayer(nn.Module): """ Args: d_model: the number of expected features in the input (required). nhead: the number of heads in the multiheadattention models (required). dim_feedforward: the dimension of the feedforward network model (default=2048). About: """ # One multi-head attention + one feed-forward def__init__(self, d_model, n_head, dim_feedforward, dropout = 0.1) -> None: super().__init__() self.self_attn = MultiheadAttention(d_model, n_head) self.norm_1 = nn.LayerNorm(d_model) # Implementation of Feedforward model(Two linear transformation together with one dropout) self.linear1 = nn.Linear(d_model, dim_feedforward, ) self.dropout = nn.Dropout(dropout) self.linear2 = nn.Linear(dim_feedforward, d_model) self.norm_2 = nn.LayerNorm(d_model)
def__ff_block(self, x): # feed forward layer contains two linear out = F.relu(self.linear1(x)) out = self.dropout(out) out = self.linear2(out) defforward(self, src, src_mask): out = src out = self.norm_1(out + self.self_attn(out, src_mask))# 这里在pytorch的官方实现中在self_attention后还加了一个dropout out = self.norm_2(out + self.__ff_block(out)) return out
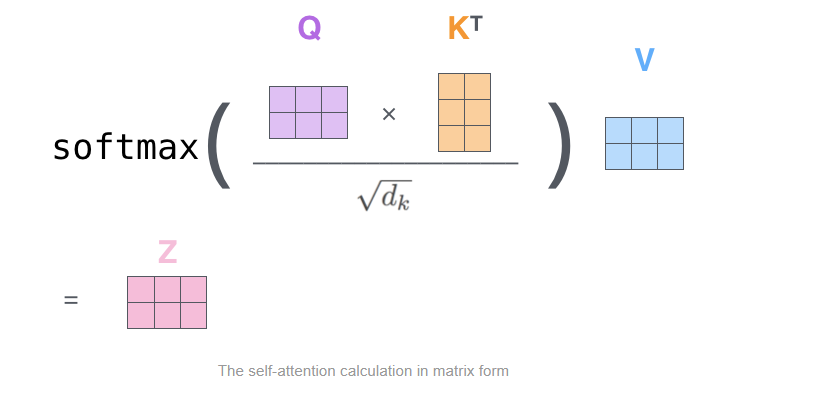
# Merge the multi-head back to the original shape out = tf.concat(tf.split(out, self.h, axis=0), axis=2) # [bs, q_size, d_model]
# The final linear layer and dropout. # out = tf.layers.dense(out, self.d_model) # out = tf.layers.dropout(out, rate=self.drop_rate, training=self._is_training)
return out
以上的实现其实和博客内的内容有点相左,博客写的是:
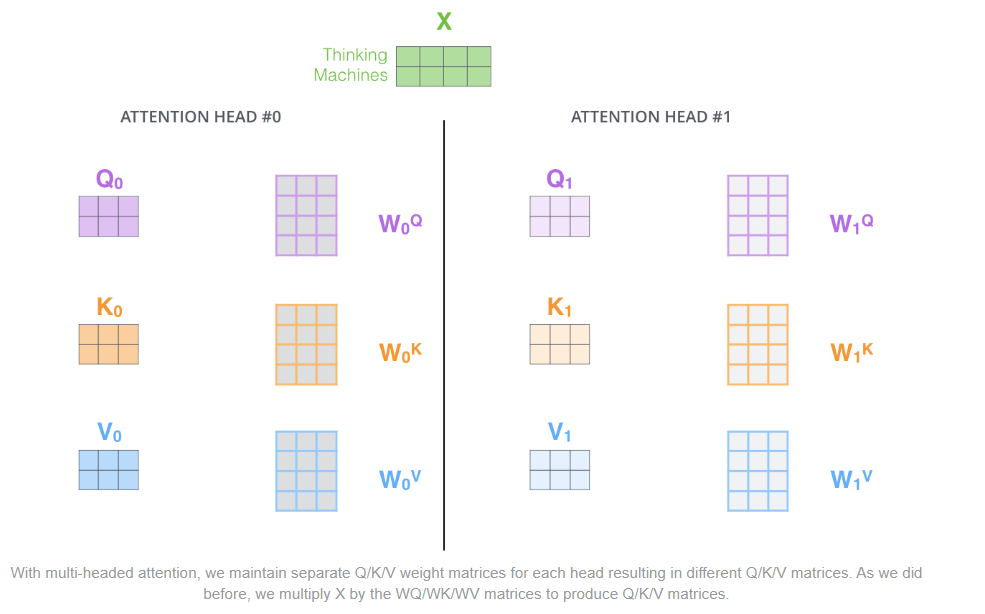
As we’ll see next, with multi-headed attention we have not only one,
but multiple sets of Query/Key/Value weight matrices (the Transformer
uses eight attention heads, so we end up with eight sets for each
encoder/decoder). Each of these sets is randomly initialized. Then,
after training, each set is used to project the input embeddings (or
vectors from lower encoders/decoders) into a different representation
subspace.
However, the important thing to understand is that this is a logical
split only. The Query, Key, and Value are not physically split into
separate matrices, one for each Attention head. A single data matrix is
used for the Query, Key, and Value, respectively, with logically
separate sections of the matrix for each Attention head. Similarly,
there are not separate Linear layers, one for each Attention head. All
the Attention heads share the same Linear layer but simply operate on
their ‘own’ logical section of the data matrix.