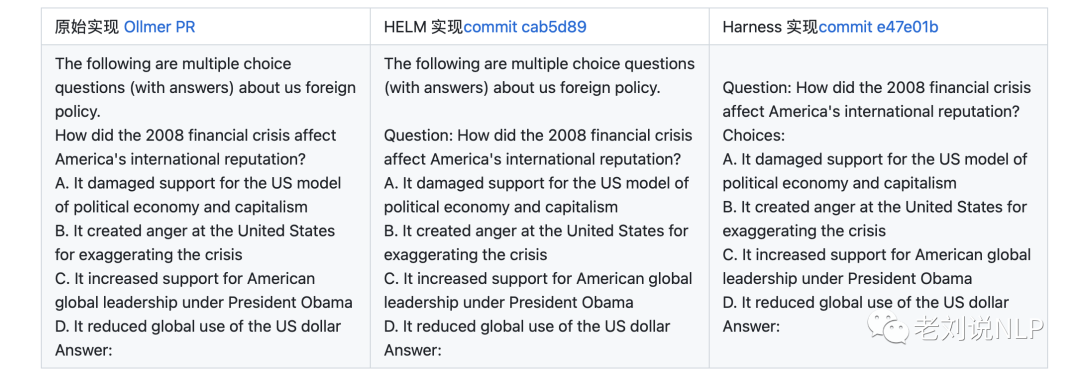
MMLU (Massive Multitask Language
Understanding) is a new benchmark designed to measure knowledge
acquired during pretraining by evaluating models exclusively in
zero-shot and few-shot settings.
关于如何使用这个benchmark,参考MMLU原始实现,作者写的是用chatgpt来产生答案,prompt为:prompt = "The following are multiple choice questions (with answers) about {}.\n\n".format(format_subject(subject))
data = [ "A multilayer perceptron (MLP) is a class of feedforward artificial neural network (ANN)", "The term MLP is used ambiguously, sometimes loosely to any feedforward ANN, sometimes strictly to refer to networks composed of multiple layers of perceptrons (with threshold activation); see § Terminology", 'Multilayer perceptrons are sometimes colloquially referred to as "vanilla" neural networks, especially when they have a single hidden layer.[1]', "An MLP consists of at least three layers of nodes: an input layer, a hidden layer and an output layer. Except for the input nodes, each node is a neuron that uses a nonlinear activation function.", ] model = transformers.GPT2LMHeadModel.from_pretrained("gpt2") tok = transformers.GPT2Tokenizer.from_pretrained("gpt2") tgs = [] for dat in data: random.seed(dat) # print(model(tok.encode(dat, return_tensors="pt"))[0][0]) toks = tok.encode(dat, return_tensors="pt") ind = random.randrange(len(toks[0]) - 1) logits = F.log_softmax(model(toks)[0], dim=-1)[:, :-1] # [batch, seq, vocab] res = torch.gather(logits, 2, toks[:, 1:].unsqueeze(-1)).squeeze(-1)[0] tgs.append(float(res[ind:].sum()))
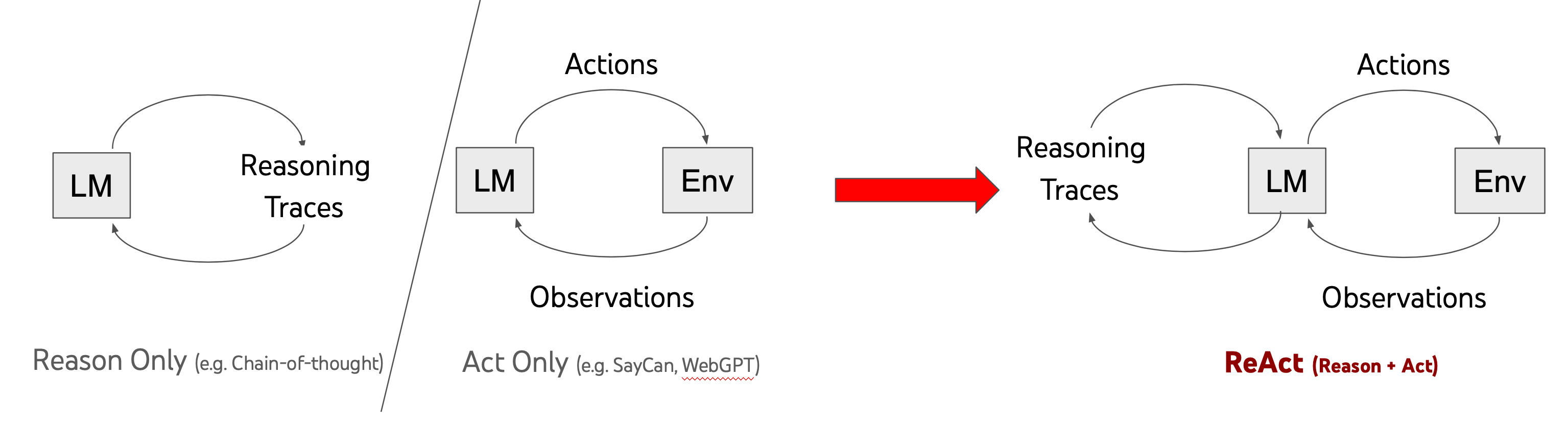
Recent months have seen the emergence of a powerful new trend in
which large language models are augmented to become “agents”—software
entities capable of performing tasks on their own, ultimately in the
service of a goal, rather than simply responding to queries from human
users
从上面的例子就可以理解作者提出的办法就是将thought和action结合起来了,也就是单纯的思考比如chain
of
thought并不能很好的回答问题,受制于预训练模型自己模型内存储的知识,而如果只有action呢?就是不停的去搜索,如果搜索不到正确的答案那也是白搭。其实我理解就是作者提出我们要做一个通用的人工智能,你要告诉他在行动的时候也要思考,思考清楚之后再去考虑下一步已经采取什么样的行动,同时每一次行动也会从环境中得到反馈,比如作者举的第二个例子,你去countertop(台面)的时候,你看到了苹果,面包,胡椒粉瓶子和一个花瓶,既然我们要把胡椒粉瓶子放到抽屉里,那就可以拿走胡椒粉瓶子啦!其实这也好理解,一个优秀的人其实也是要边做边思考的,所以就形成了作者提出的prompt新范式:
1 2 3 4
Thought: ... Action: ... Observation: ... ... (Repeated many times)
思路大概就是和斯坦福的dsp一个思路,用户问一个问题,第一种方式就是直接把这个问题抛给llm,让它去回答,第二种就是在把问题抛给llm之前先过一道retrival模型,这个模型会抽取一些和回答这个问题相关的一些context,将这些context加入prompt中,然后再抛给llm。这有一个专门的名词,在Demonstrate-Search-Predict:
Composing retrieval and language models for knowledge-intensive NLP
中有所介绍:
retrieve-then-read。有兴趣的可以再看一下斯坦福在做这部分工作时出的notebook介绍,看完你就知道为啥要retrieve一些context加入到prompt中去。
with Run().context(RunConfig(nranks=4, experiment='notebook')): # nranks specifies the number of GPUs to use. config = ColBERTConfig(doc_maxlen=doc_maxlen, nbits=nbits)