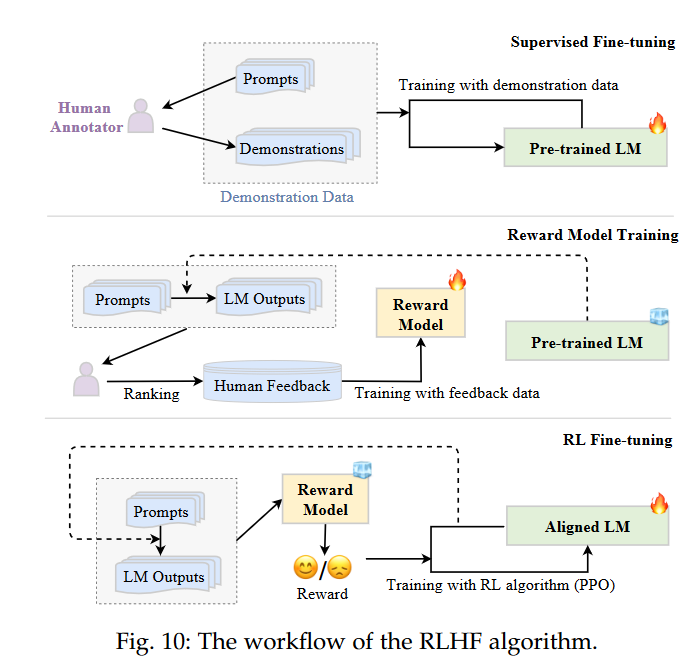
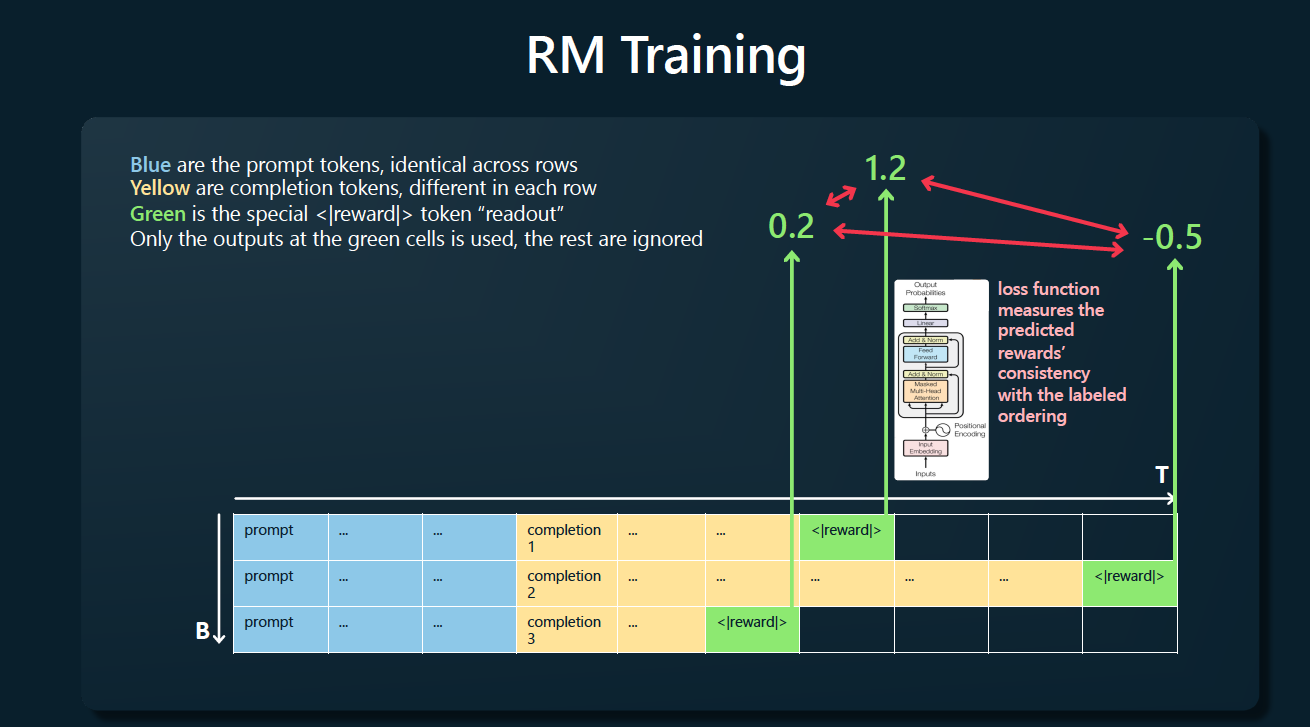
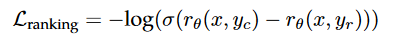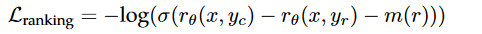LLaMA系列模型浅析
这篇博客主要记录博主在探索meta开源的llama大模型,包括它的数据,training代码以及评测方法。之所以想记录下来,主要是因为llama的论文写的极其的细致,完美践行了开源这个词(感谢meta!),第二个原因是它的文档以及社区都很活跃,使用人群广泛,我们可以借助很多中文社区的复现情况去一探大公司在实现一个大模型时候的考量,以及思考它为什么会这样做。
之前写过一篇关于斯坦福的alpaca的代码的解析,后来看过很多关于微调大模型(supervised finetuning)的代码仓库,大家的实现思路基本上都可以追溯到alpaca的这份代码。
首先我会将所有我参考的资料罗列在前面,方便大家查找: - llama代码仓库 这个仓库是介绍如何下载llama模型 - llama "食谱" 一开始我想在上一个llama仓库中找到相关的train代码,找了半天发现根本没有。后来才发现meta官方将所有finetune(pretrain from scrach)的代码放在这个仓库,适合developer - Llama 2: Open Foundation and Fine-Tuned Chat Models llama2的research paper。强烈建议食用
中文社区的LLama的工作 - Chinese LLaMA Alpaca2
这个仓库同样有配套的文章Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca
这个仓库的工作主要是两个:
- 扩充了llama原来的token,也就是中文的那部分
- 用新的中文数据在llama上进行了continue pretraining,并且发布了在instruction数据上的微调模型
研究思路很简单,在别人模型上继续预训练,并参照alpaca对预训练的模型进行instruction finetune让其具备follow instructions的能力。我们首先从这个Chinese LLaMA代码仓库看起。