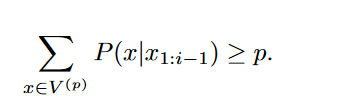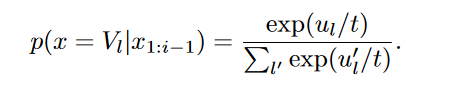QA(question answering)
QA是什么?
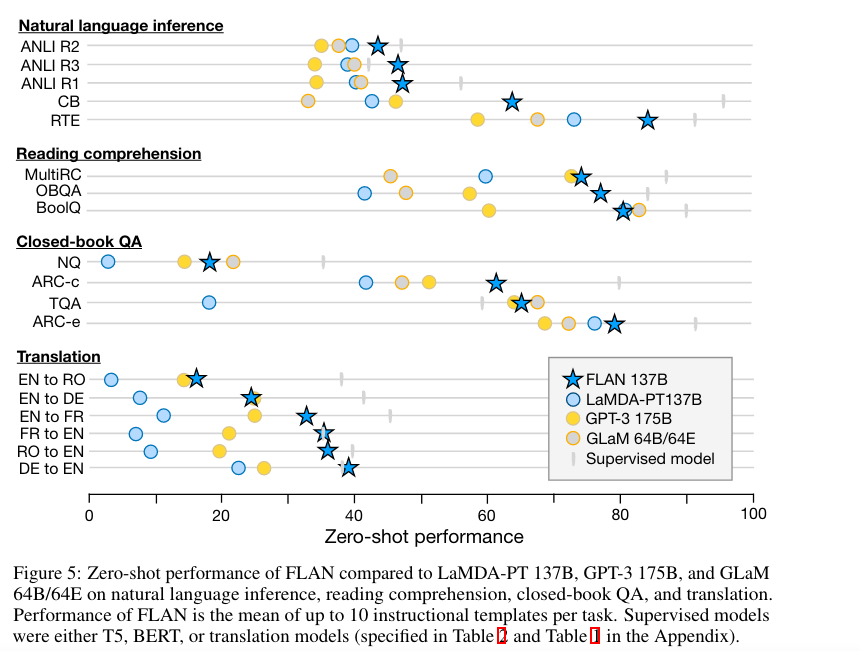
直观上理解,QA就是用户给出一个question,系统(模型)给出一个answer。它和reading comprehension还是不一样的,在paper中对于这两个问题做了归纳:
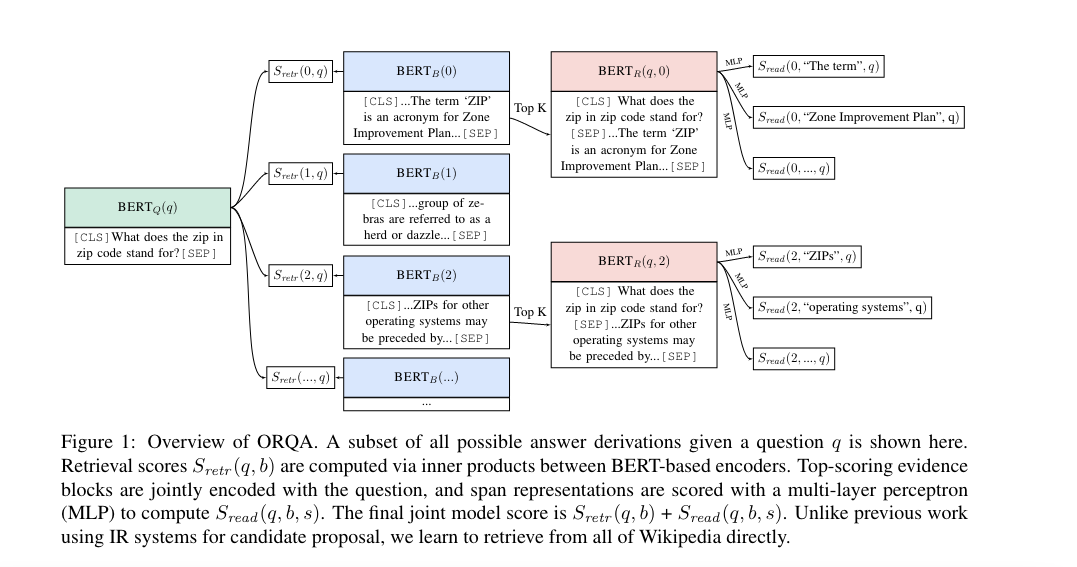
reading comprehension问题,我们的任务是从一个paragraph中找出answer:comprehend a passage of text and answer questions about its content (P,Q)-> A,也就是我们事先不仅有question,还有一段paragraph,我们只需要找出answer在这个paragrapg中的位置(span),但是对于open-domain的QA来说,我们事先是不知道anwer在哪儿的,比如上图中unsupervised QA。那么对于这一类open-domaiin的问题如何解决?最常见的就是retriver-reader架构,就是我们先从一大堆语料库中挑选出我们的paragraph,然后对于这一些paragraph,我们用reading comprehension的技术再来定位answer在哪里。上面这篇paper就是应用的这种思想,提出了ORQA,这是19年的文章,想法很典型。
上文提到的斯坦福的数据集SQuAD是使用的最广泛的reading comprehension数据集,它的组成形式是(passage, question,answer),每一个answer都是passgae里面的一个segment。

这就有它的局限性,因为有一些问题的回答是不会在passage中找到的,所以它不能用于open-domain的task,它完全是一个监督性任务的数据集,目前在这个数据集上最好的模型的表现已经超越了人类,可以说是"almost solved"。
Reading Comprehension
首先我们可以先从比较简单的问题开始解决,reading comprehension可以说是QA的一个子问题。第一步搞明白问题定义:
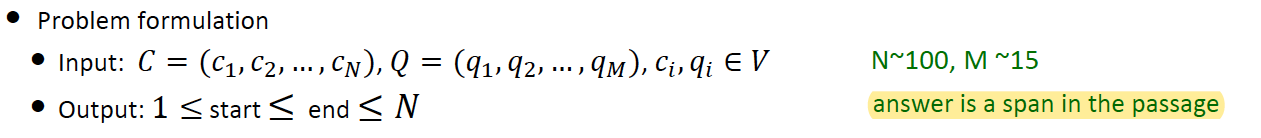
2016年-2018年,主要用于解决RC的方法是LSTM+attention的模型架构,这些模型主要有15年的attentive reader、16,17年的stanford attentive reader、17年的match-LSTM、17年的BiDAF、17年的dynamic coattention network、17年的DrQA、17年的R-Net、17年的ReadoNet。2019年开始,主要是18年Bert出来之后,大家普遍开始采用finetune BERT来解决这个问题,值得一提的是在BERT的原文paper中下游任务也使用了SQuAD来做了实验,作者用于预测start和end的方式也设计的很精巧。
stanford attentive reader
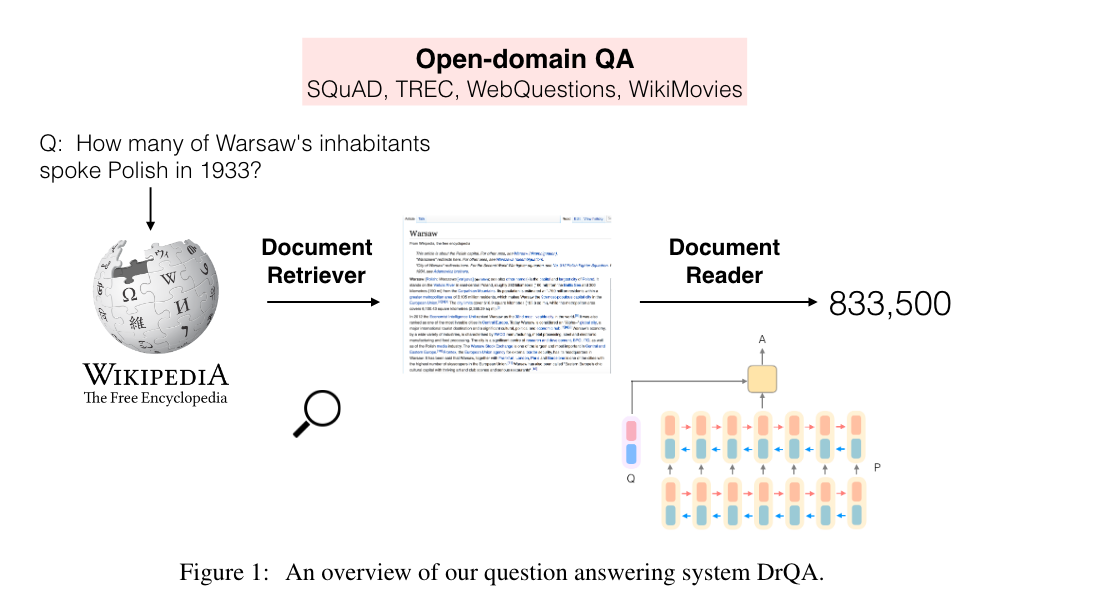
这篇文章在logistic regression的基础上(SQuAD数据集)有了巨大的进步,算是18年之前lstm+attention架构的集大成者。思想很简单,但里面很多细节,比如在编码passage的时候用了好多来源的vector进行拼接,然后再输入斤lstm中。但整体架构和机器翻译领域的发展历程是一样的,在transformer没有出现之前,大家都在lstm上做了很多创新,attention加入计算是其中一种,DrQA将多个来源的向量拼接也是一种,感兴趣的可以读一下原文:Reading Wikipedia to Answer Open-Domain Questions。作者是cs224n的QA这门课的讲师,也是一位华人小姐姐。其实我在看cs224n QA这一讲的ppt时感觉斯坦福的这门课着重讲解了stanford attentive reader这一系列的模型,不知道有没有私心。
这之后还出现了bidirectional attention的,例如BiDAF,就是不仅计算了query2Context的attention weights,也计算了Context2Query的attention weights,将这两者和context原来的lstm值再输入进一个双层LSTM进行start,end的预测(很复杂就是了),虽然也不知道为啥这么做就会有一个不错的performance,模型架构越来越复杂,卷死了。
但不管怎么说,在transformer被大家普遍使用之前,rnn+attention的这种模式是最好的解决办法了,俗称SOAT。
Bert用作reading comprehension
自从18年开始,在reading comprehension这个任务上,谷歌出了bert,成就了新的历史,一下子F1从79.4(DrQA)升级到了91.8,人类在SQuAD上的表现才91.2,所以算是超越人类表现了。
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 这篇文章的4.2节详细介绍了预训练完成之后的bert如何在SQuAD这个下游数据集上进行finetune的。
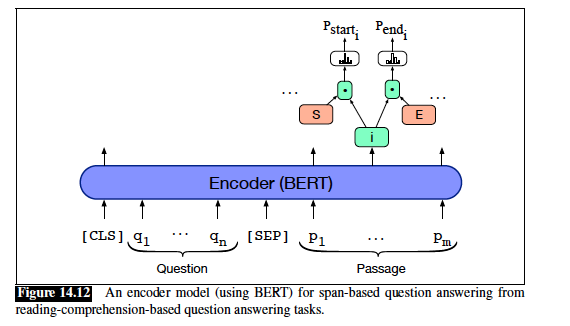
上面这幅图更好的解释了Bert在finetune的时候如何做RC这个任务的。首先我们将question和paragraph拼接在一起,中间使用[SEP]连接。然后将这一串字符串整个输入进预训练好的Bert。对应的bert输出了同样长度的一连串向量,这时我们只取paragrapgh那一部分对应的向量们。第二步加了两个独特的向量,这两个向量是下游任务新增的,需要通过finetune时更新参数,分别是start S和end E向量。为了得到paragrapgh中每一个token它时span-start的概率,采用如下公式:
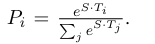
同样对于每一个token成为泡影span-end的概率,也对E采用同样的计算方式。到这一步我们就得到了paragrapgh中每一个token它们成为span-start和span-end的概率。第三步如何通过这些概率值得出我们的answer所在的span?
作者的做法是对每一个candidate span都计算一个分数: \[ S*T_i+E*T_j \] 选取得分最大的那个span作为预测值。计算loss时有一点不太一样,刚刚说的是predict,loss的计算是用的负log \[ L = - logP_(start^s) - logP_(end^e) \] 这里可能会有点迷惑。其实训练数据拿来时,对于paragraph中每一个token我们都会有一个label表示它是否是start还是end,是就是1,不是就是0.那么我们在做预测的时候,上面的第三步骤已经得到了每一个token的成为start还是end的概率,那么这时候我们就能用交叉墒来计算loss了。注意这里我们用的是softmax,所以我们应该是计算softmax的loss。另外这里只会计算到真正的start和end的那两个token上的loss,因为其他token的groudtruth label都是0。
SpanBERT
这篇是在Bert基础上改进的,主要改进点在于improve了Bert在pretrain时候的两个task:1. mask 2. next sentence prediction。同样是chen的文章:(Joshi & Chen et al., 2020): SpanBERT: Improving Pre-training by Representing and Predicting Spans
To finish
SpanBert在谷歌的bert基础上又将performance提高了许多。
open-domain question answering
这个问题在Speech and language processing的第三版的14章节进行了详细介绍,它也可以叫做是information-retrieval(IR) based QA。它首先要做的是从很大的语料库中搜索出相关的passage,然后第二步运动reading comprehension的算法从这些passage中找出answer(spans of text)。从一堆语料库里找到相关的passage,这个过程称之为information retrival。
IR能想到的最最简单的做法就是将query和语料库中的每一个passage都编码成一个向量,然后计算这些向量之间的相似度,也就是score,分数越高的就是跟query越相似,那么就可以得出语料库中和query最相关的那些passage了。那么将query和passage们编码成向量有很多种方法,最简单的方法就是TFIDF,还有tfidf的变种BM25。这些方法现在已经不再采用,更多的是用Bert,俗称dense vectors,这是和tfidf这种稀疏向量相对应的叫法。
具体做法是:
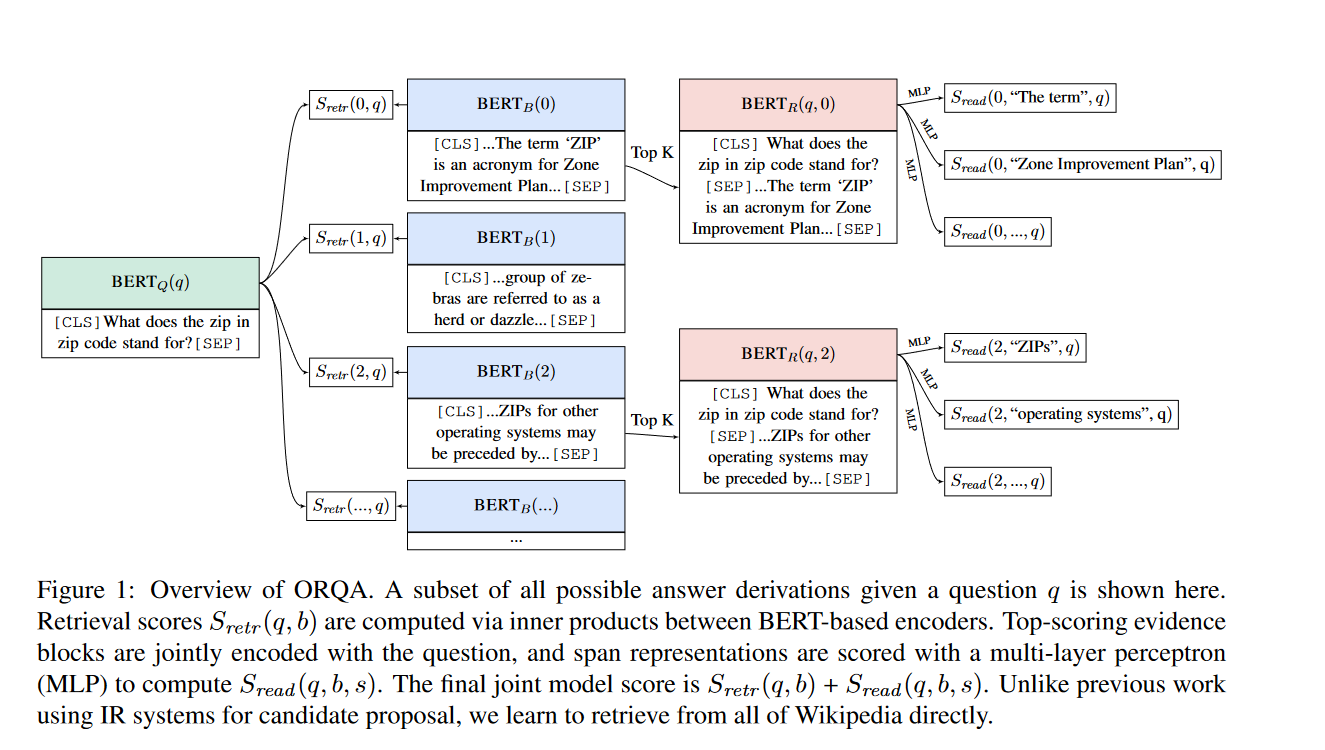
分别用两个不同的bert分别编码query和passage们,然后将query的向量[CLS]和passage的向量[CLS]点积,这个点积的结果就作为query和passage的相似度得分。上面这张图片是将retriver和reader一起训练的,当然也可以单独用query和answer训练retriver
用生成模型来做QA
由于LLM的兴起,大家开始发现用生成模型来做QA更能回答复杂的问题。比如现在的GPT系列模型。它完全摈弃了抽取信息和从passage中寻找answer所在位置的环节,有点黑科技,就好像模型将所有的知识都记到脑子里去了。但也带来了新的问题,用户没有办法知道模型是从哪里找到的答案。