tensorflow中lstm,GRU
GRU

其实单看输出,GRU的输出是和简单的RNN一样的,都只有一个hidden_state。所以在tensorflow中它的输出其实和RNN layer一样:
1 | import tensorflow as tf |
其中有两个可以传递给GRU的参数,一个是return_state,一个是return_sequence。两个值都是bool类型。如果单独传递return_sequence=True,那么输出将只有一个值,也就是每一个时间步的序列:
1 | gru = tf.keras.layers.GRU(4, return_sequences=True) |
如果单独传递return_state=True,那么输出将会是两个值,可以仔细看官方文档中的说明是Boolean. Whether to return the last state in addition to the output. Default:False.`也就是output和最后的hidden_state会一起输出,并且output会等于final_state:
1 | gru = tf.keras.layers.GRU(4, return_state=True) |
如果单独传递return_sequences=True,LSTM将只返回整个序列!
1 | lstm = tf.keras.layers.LSTM(4,return_sequences=True) |
那如果两个值都设置成True呢?这将返回两个输出,第一个输出是整个序列,第二个输出是最终的state。注意这里并没有output了,因为output其实是sequence中最后一个序列sequence[:,-1,:]
1 | gru = tf.keras.layers.GRU(4, return_sequences=True, return_state=True) |
LSTM
轮到LSTM,因为架构上跟GRU有点区别,所以在返回结果上就多了一个carry_state.
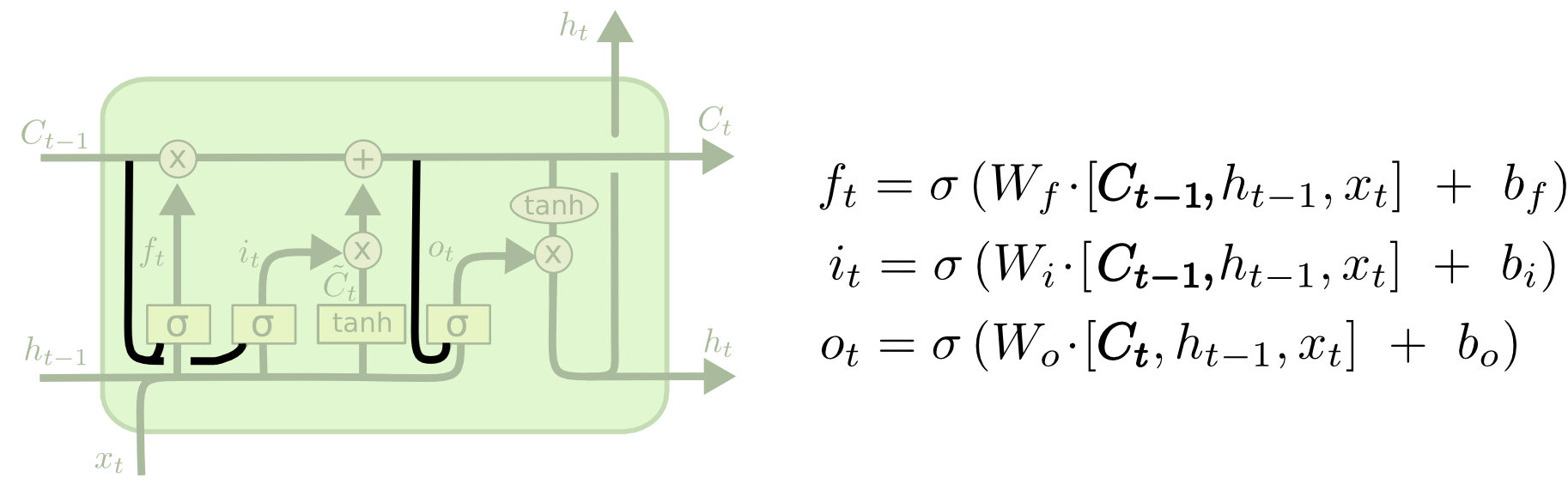
想要了解LSTM的具体计算,参考博客
在tensorflow中一样有return_state和return_sequences:
1 | inputs = tf.random.normal([32, 10, 8]) |
如果单独传递return_state,这里和GRU不一样的地方在于lstm有两个state,一个是memory_state一个是carry_state
1 | lstm = tf.keras.layers.LSTM(4,return_state=True) |
如果同时设置True
1 | lstm = tf.keras.layers.LSTM(4,return_sequences=True,return_state=True) |
GRU vs LSTM
至于我们在训练模型的时候选择哪一个cell作为RNN的cell,cs224n课程给出的答案是:
Researchers have proposed many gated RNN variants, but LSTM and GRU are the most widely-used.
Rule of thumb: LSTM is a good default choice (especially if your data has particularly long dependencies, or you have lots of training data); Switch to GRUs for speed and fewer parameters.
LSTM doesn’t guarantee that there is no vanishing/exploding gradient, but it does provide an easier way for the model to learn long-distance dependencies.
在2023年的今天,lstm也不再是研究者青睐的对象,最火的模型变成了Transformer:

这里也贴出2022年的最新WMT的结果