如何对开源大语言模型微调?需要多少数据?
随着各大语言模型的开源,很多研究在没有计算资源的情况下,唯一可想的办法就是在各大开源模型上利用垂直领域的数据集来finetune开源大模型,充分利用pretrained模型的能力,而又能让它解决特定的任务。 斯坦福的羊驼alpaca模型的发布掀起了instruction tuning的一阵狂潮,国内很多工作也在模仿Stanford这个工作方法做自己领域的大模型,其实在接触这些工作的时候我一直有一个疑问,就是什么时候我们该finetune?手里有多少数据的时候你可以finetune。
如果我们要开展微调,数据以及如何组织数据形式和微调的方式是两个主要问题。
微调的方式
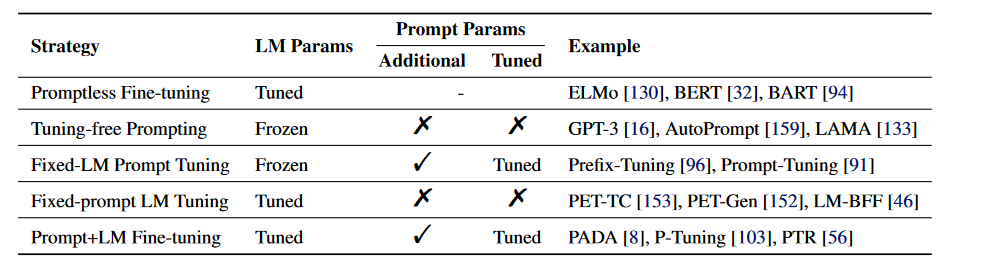
现有的LLM规模太大,因此完全微调模型已并非易事。因此无论学界还是业界都需要一种高效的方法在下游任务数据上训练,这就为参数高效微调(Parameter-efficient fine-tuning,PEFT)带来了研究空间。PEFT的目的是只训练一小部分参数(可以是大模型自身的,也可以是额外引入的)就能提升模型在下游任务的效果。
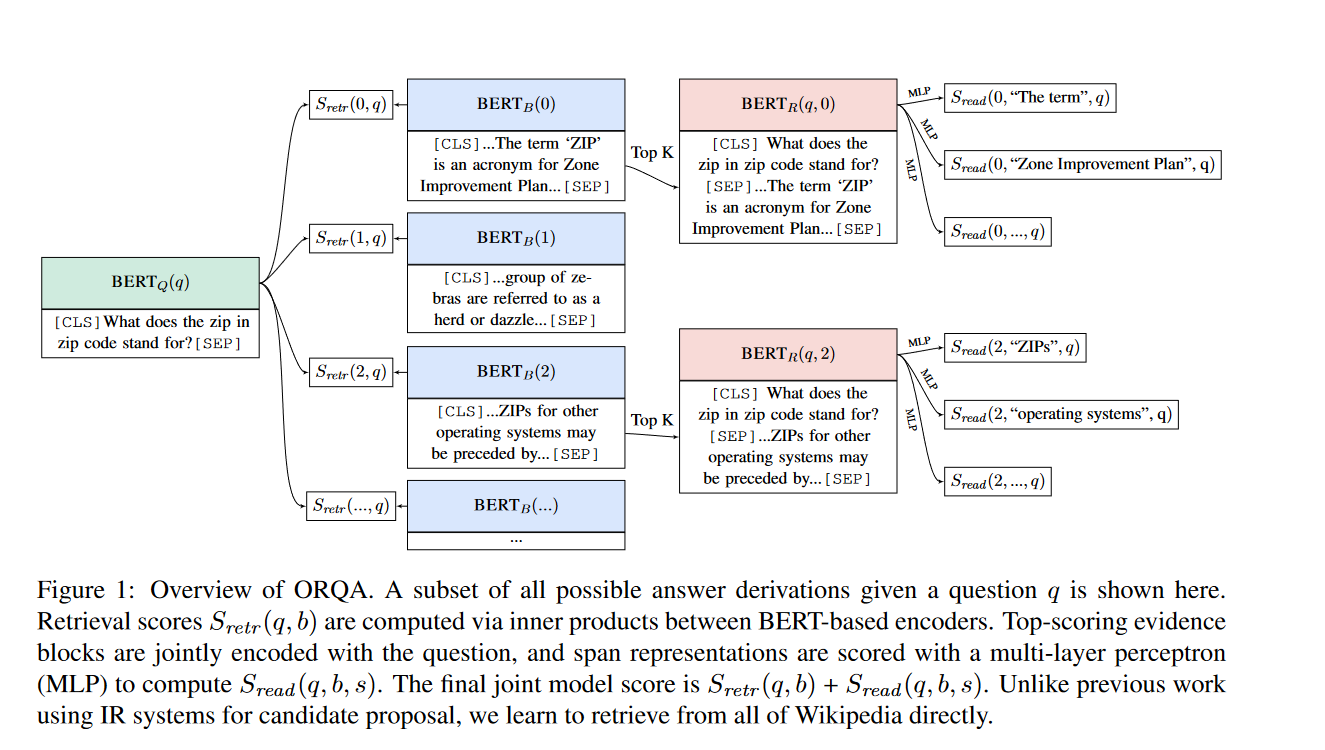
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning 一文总结了现有peft的主要方法,并做了分类:
可以看到lora也就是我们现在经常用到的微调手段被分配到了reparametrization-based里面。并且在additive这个分类里,又分了两个子类:adapter-like和soft prompts。对于每一个分类的解释可以看paper或者参考这篇知乎博客
我这里只做简单的对比:
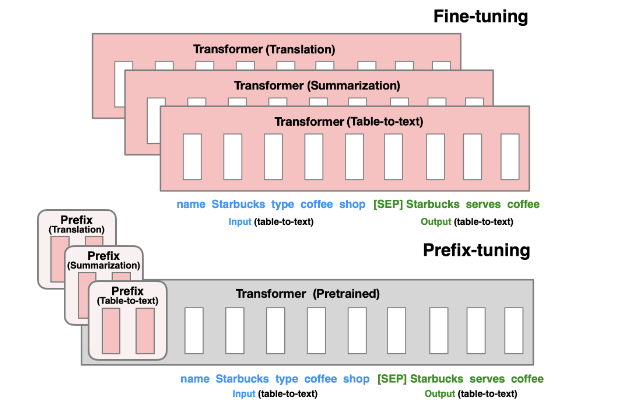
- prefix tuning,prompt tuning根本就是为了解决人工为每一个任务构造prompt太过于随机性,而且构造的模板有时候是离散化的;另外一个痛点就是如果对模型在下游任务上进行全参数调整,每一个任务得保存一份参数副本,对存储和训练都是考验。所以这一类方法就是让模型通过学习来自动寻找最合适的prompt,称之为soft prompt.LLM那一部分的参数不做调整,只调整添加的这一部分参数。之后清华大学提出的ptuning和ptuning v2版本,可以简单的将P-Tuning认为是针对Prompt Tuning的改进,P-Tuning v2认为是针对Prefix Tuning的改进。
- lora这一类方法(AdaLoRA,Qlora)基于的理论是:将LLM在下游任务进行微调时发现改变的参数都是哪些低秩矩阵,所以这些方法重构了一种低秩矩阵运算,这些矩阵里面的参数就可以代表下游任务的知识,这样将LLM的预训练参数和这部分参数进行合并之后就可以适配下游任务了。
微调实践Applications
这一章节主要介绍一些值得关注的微调实践工作,可以给我们在实际工作中提供一些微调的思路,比如看看别人数据集是如何组织的,有多少的数据量,针对什么任务有了performance的提高,还有做evaluation是咋做的。
Stanford Alpaca
这是开创instruction tuning工作的鼻祖,而且斯坦福的代码写的很优秀,特别是用GPT3生成instruction-input-output那一部分,把代码通读一遍可以加深self-instruct方法的理解。而且斯坦福的这个数据集只有52k条,但是有意思的是它在组织这52k条数据的时候是需要充分保持task的多样性的,毕竟我们知道instruction tuning当时在 Finetuned Language Models Are Zero-Shot Learners 文中被提出的时候,其实是为了提高模型在unseen task上的zero-shot能力,它有一个重要的前提是finetune的task要多样,这个非常重要!
现在有一些国内的工作就是直接弄了一些数据就开始finetune,然后叫自己是instruction tuning,我觉得不太合理。
最近出了一个工作: LIMA: Less Is More for Alignment,在LLaMa-65B基础上用1000条instruction数据训练的模型,在43%的情况下,LIMA可以超过或者和GPT4平齐,这真的很厉害了,毕竟只用了1000条数据,而且作者也用斯坦福的方法复刻了52k微调llama-65B的大羊驼,发现还是LIMA优秀一点,作者猜测是因为数据集质量,这1000条数据是精心策划的。
Chatglm-6B p-tuning
基于chatglm-6B的微调项目超级多,chatglm有天然的中文优势,所以国内好多语言模型都是基于清华的这个语言模型做的工作。chatglm-6B给出的官方github repo中包含了p-tuning v2的代码, p tuning v2的原理就是将应该人工写的那一部分prompt用参数来学习,LLM预训练好的那一部分参数固定住,只更新添加的这部分参数。参考chatglm-6B自己给出的再ADGEN(广告生成的数据集)上finetuneg chatglm6B的代码: https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning, 这部分代码的数据组织部分蛮有意思的,数据集长这样:
1 | { |
也就是不像alpaca数据集有instruction了,只是一个映射关系,而且在main.py训练代码里也没有见到处理数据sample时要给每一个数据前加instruction,唯一加的就是在content前加了一个“问:”,在summary前加了一个“答:”。
Gorilla
这是一个微调LLaMa-7B让LLM实现用语言方式让LLM返回API调用代码的工作。
参考:
- https://gorilla.cs.berkeley.edu/
- Gorilla Github Repo
- Gorilla: Large Language Model Connected with Massive APIs
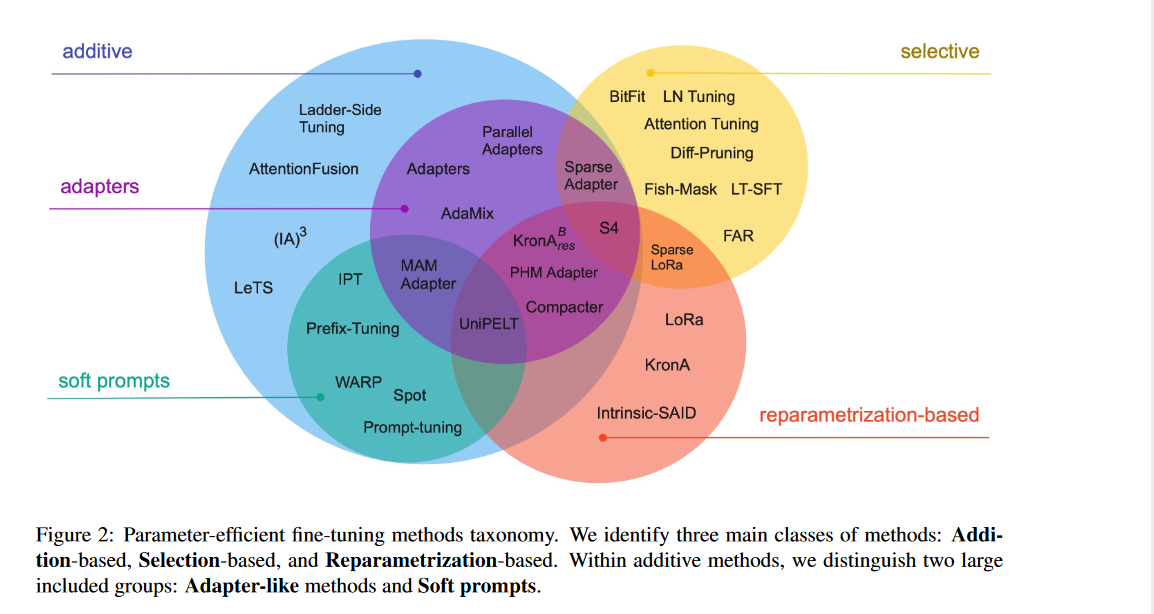
产生数据集的方式跟alpaca如出一辙,利用了self-instruct方式,让GPT-4来产生instruction-API的训练数据。而且它分了两种模式来训练,一种是有retriever的模式,在instruction中添加了数据库里关于这个API的帮助信息,一种就是instruction-API的格式。因为repo里并没有开源这部分的训练数据,所以我们也只能看论文来猜测数据是长这样的,等作者公布了数据可以再补充这部分数据到底长什么样子。
我们在使用这个model进行推理时,输入给他的就是一串我呢本,告诉它你想获得一个怎么样的API,比如“I would like to identify the objects in an image”或者更模糊一点:“I am going to the zoo, and would like to track animals”。在zero-shot模式下这个instruction会直接给到gorilla,模型会给你返回一串API调用的代码,像这样:

总体来说这个项目想法蛮有意思的,就是很多东西暂时还没开源,我们拭目以待吧,现在就用用就行。